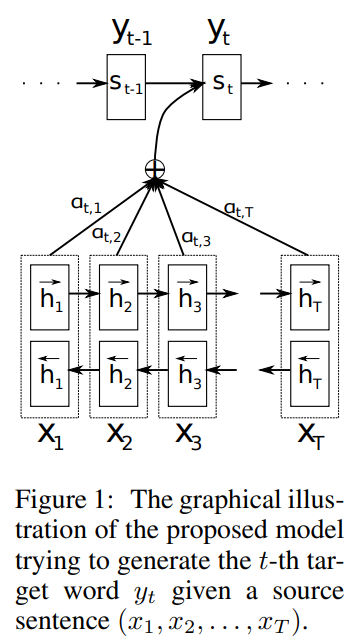
이전의 Seq2Seq 모델은 하나의 인코더 LSTM을 사용해 입력 문장을 하나의 고정된 크기를 가지는 Context vector 로 변환하고, 이 Context 벡터를 디코더 LSTM의 입력으로 사용해 출력 문장을 뽑아내는 방법을 사용하였습니다. 이 구조의 문제점 중 하나는 병목(Bottlenect) 현상으로 성능 하락의 주 원인입니다. 또한 하나의 Context vector 가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하된다는 문제점 또한 발생합니다. 이를 해결하기 위해 매번 소스 문장에서의 출력 전부를 입력으로 받으면 어떨까? 라는 의문점으로 시작하는 것이 본 논문의 핵심입니다. 이번 논문은 Seq2Seq 모델에 어텐션(Attention) 메커니즘을 적용한 논문입니다. 디코더의 개선에 ..