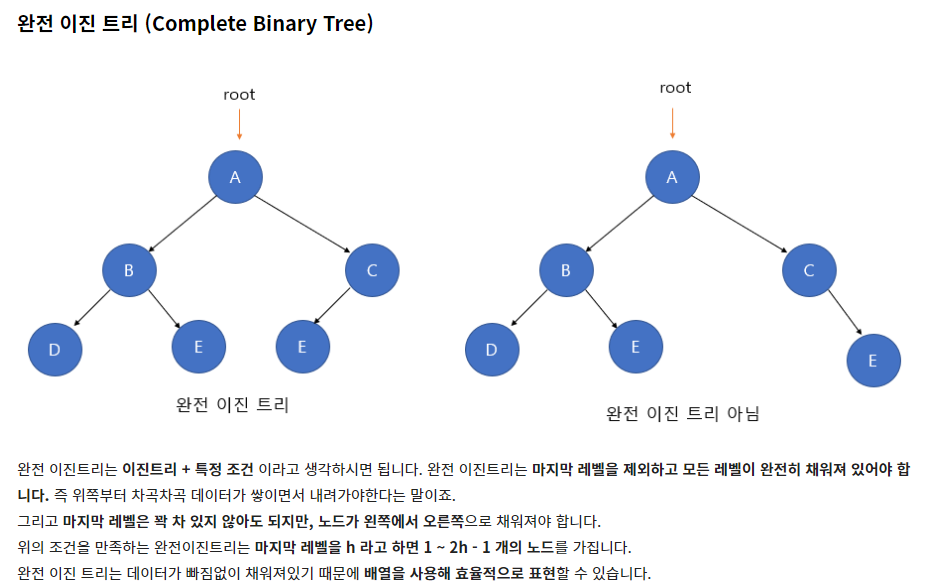
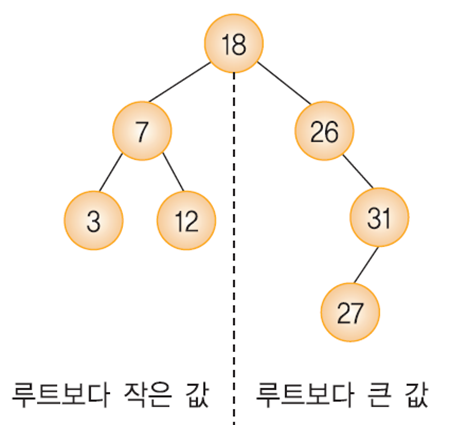
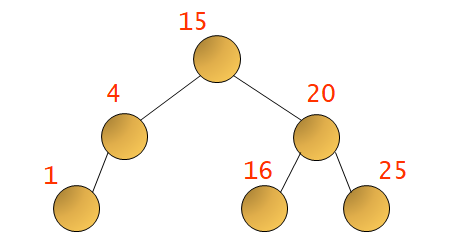
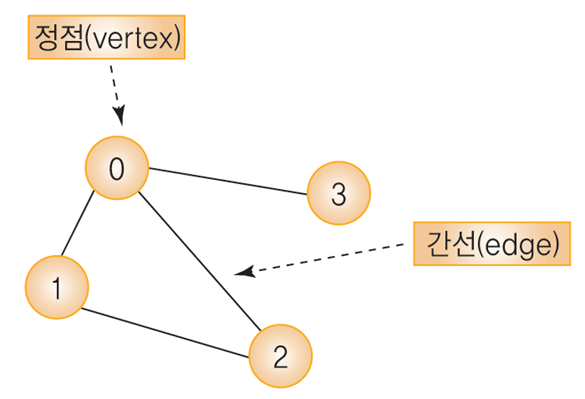
[C 자료구조] 그래프 ADT 구현 : 인접행렬 / 인접리스트 n = 0; for (row = 0; row adj_mat[row][col] = 0; } Graph 구조체 안에는 인접 행렬을 나타낼 2차원 배열과 정점의 개수를 저장할 변수를 선언합니다. 그 이후 songsite123.tistory.com 지난 포스팅에서 인접 행렬과 인접 리스트로 그래프를 구현해보았죠. 오늘은 그렇게 구현한 그래프의 탐색 연산을 구현하는 방법에 대해 알아보겠습니다. 그래프의 탐색은 가장 기본적인 연산으로 하나의 정점으로부터 시작해서 차례대로 모든 정점들을 한 번씩 방문하는 것 입니다. 그래프의 탐색 방법은..