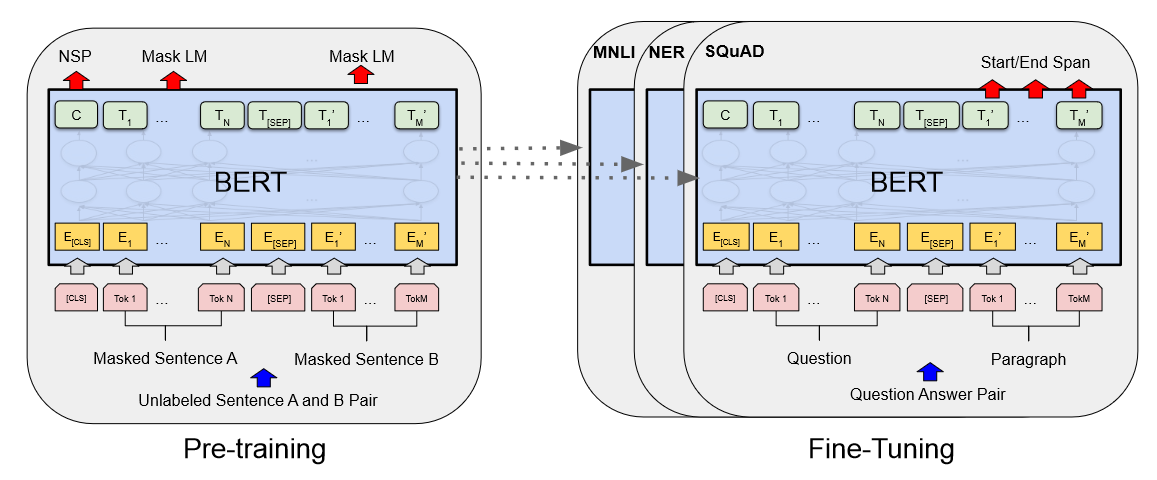
BERT 이전 기존 NLP에서도 Pre-trained 된 모델을 Fine-tuning 사용하는 기법은 존재했지만, Pre-train에서 양방향이 아닌 단방향의 아키텍처만 사용할 수 있다는 한계점이 있었습니다. 그러나 기존 모델들은 LSTM이나 RNN처럼 문장을 학습할 때 순차적으로(Left to Right) 읽을 수 밖에 없다는 문제점을 지니고 있었습니다. 단어 임베딩의 경우 Transformer를 사용해 Attention을 통해 관계성에 대해서는 잘 파악하도록 만들어낼 수 있지만, 결국 예측시에는 단방향으로 읽어 예측해야하기 때문에 이전 토큰만 참조할 수 있다는 단점이 있습니다. 따라서 이전 논문들은 양방향에서의 문맥 정보가 모두 중요한 token-level task에서 좋은 성능을 보이지 못했는데 이..