BERT 이전 기존 NLP에서도 Pre-trained 된 모델을 Fine-tuning 사용하는 기법은 존재했지만, Pre-train에서 양방향이 아닌 단방향의 아키텍처만 사용할 수 있다는 한계점이 있었습니다. 그러나 기존 모델들은 LSTM이나 RNN처럼 문장을 학습할 때 순차적으로(Left to Right) 읽을 수 밖에 없다는 문제점을 지니고 있었습니다. 단어 임베딩의 경우 Transformer를 사용해 Attention을 통해 관계성에 대해서는 잘 파악하도록 만들어낼 수 있지만, 결국 예측시에는 단방향으로 읽어 예측해야하기 때문에 이전 토큰만 참조할 수 있다는 단점이 있습니다. 따라서 이전 논문들은 양방향에서의 문맥 정보가 모두 중요한 token-level task에서 좋은 성능을 보이지 못했는데 이를 해결하기 위한 MLM(Masked Language Model)을 사용해 bidirectional 한 문장도 담을 수 있는 BERT model 을 제시한 논문입니다. BERT는 Pre-train을 통해 task에 대한 학습이 아닌 language 자체에 대한 bidirectional 한 context를 학습 한 뒤 task에 맞게 Fine-tuning을 하여 11개의 NLP task에서 SOTA 를 달성한 모델입니다.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Abstract
본 논문에서는 트랜스포머의 양방향 인코더 표현의 약자인 BERT(Bidirectional Encoder Representations from Transformers) 라는 새로운 언어 표현 모델을 소개합니다. 최근의 언어 표현 모델과 달리 BERT는 모든 Layer에서 unlabeled text 의 양방향 context를 공통으로 결합하여 Deep bidirectional representations 를 pretrain 하도록 설계되었습니다. 결과적으로 Fine-tuning 된 BERT 모델은 다양한 task에 대해 output Layer를 하나만 추가함으로써 SOTA model 을 달성할 수 있었습니다. 이를 통해 작업 별로 아키텍처를 많이 수정하지 않고도 질문 답변, 언어 추론과 같은 광범위한 작업을 위한 SOTA model 을 달성할 수 있었습니다.
BERT는 개념적으로 단순하면서도 강력합니다. GLUE 성능 80.5%(기존 SOTA 대비 7.7% 향상), MultiNLI 성능 86.7%(기존 SOTA 대비 4.6% 향상), SQuAD v1.1 에서 F1 93.2(기존 SOTA 대비 1.5 point 향상), SQuAD v2.0에서 F1 83.1(기존 SOTA 대비 5.1 point 향상) 시키며 11개의 NLP task에 대해 SOTA를 달성하였습니다.
Introduction
언어모델에 대한 pre-training 은 다양한 NLP task에 대해 매우 효과적입니다. Pre-trained 모델을 task에 적용시키기 위한 전략으로는 2가지 방법, Feature-based 와 Fine-tuning이 있습니다. ELMo 같은 feature-based 접근 방식은 Pre-trained representation을 추가적인 feature 로 포함한 task-specific 한 아키텍처를 사용합니다. GPT 같은 Fine-tuning 접근 전략은 최소한의 task-specific 파라미터를 사용하고, pre-trained 된 모든 파라미터를 미세 조정(fine-tuning)하여 task에 대해 학습됩니다. 두 가지 접근 방식은 pre-training 동안은 같은 목적 함수를 사용하고, 단방향 언어모델을 사용하여 일반적인 언어 표현을 학습합니다.
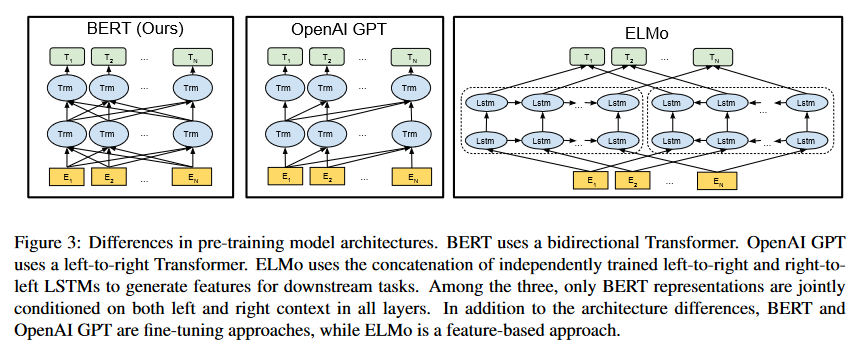
본 논문에서는 현재의 테크닉은, 특히 fine-tuning 접근 방법에 대해서 pre-trained representation의 성능을 제한한다고 주장합니다. 주된 한계점은 표준 언어 모델이 단방향이라는 점이고 이로 인해 pre-training 과정에서 사용할 수 있는 아키텍처 선택이 제한됩니다. 예를 들어 GPT 에서는 left-to-right 아키텍처를 사용하고 있고, 이 아키텍처는 모든 토큰은 오직 transformer의 self-attention layer에 있는 이전 토큰에 대해서만 연산이 가능합니다. 이러한 한계점은 문장 수준의 작업에 대해서는 단지 차선책이 될 뿐이며, question answering 와 같은 token-level task에서는 Fine-tuning이 악영향을 미칠 수 있다는 것을 뜻합니다. 따라서 이를 통해 양방향의 맥락을 통합하는 것이 매우 중요하다는 것을 알 수 있습니다.
본 논문에서는 BERT(Bidirectional Encoder Representations from Transformers) 라는 Fine-tuning 기반의 접근 방식을 개선할 수 있는 새로운 언어 표현 모델을 소개합니다. BERT는 MLM(masked language model)을 사용하여 앞서 언급했던 단방향성 제약을 완화합니다. 마스크된 언어 모델은 입력에서 일부 토큰을 무작위로 마스크하고, 이것의 목적은 마스크된 문장을 사용하여 다시 원래의 어휘를 예측하는 것입니다. left-to-right 언어 모델에 대한 pre-training과 달리 MLM은 왼쪽과 오른쪽의 context를 융합할 수 있으므로 deep bidirectional Transformer 를 효과적으로 학습시킬 수 있습니다. MLM 외에도 text-pair를 결합하여 사전 학습하는 기법인 next sentence prediction 작업도 수행합니다. 본 논문의 기여점은 다음과 같습니다.
- 언어 표현에 대한 양방향 pre-trianing 의 중요성을 보여줍니다.
- 복잡한 엔지니어링 작업이 불필요하고 다양한 문장 수준 및 토큰 수준의 task에서 뛰어난 BERT 모델을 제공합니다.
- 11개의 NLP task에 대해 SOTA를 달성합니다. 코드는 다음 주소에 있습니다. https://github.com/google-research/bert
BERT
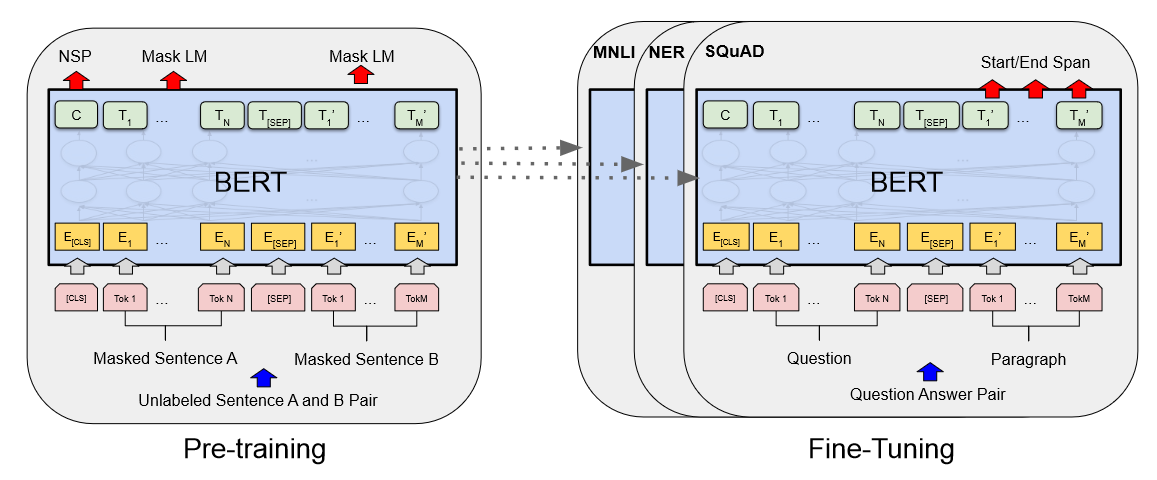
이 섹션에서는 BERT와 세부 구현을 소개합니다. BERT 프레임 워크에는 2가지 step, 1) pre-training 과 2) fine-tuning 이 있습니다. pre-training 과정에서 모델은 다양한 task들에 대한 unlabeled data로 학습, 즉 비지도 학습을 진행합니다. Fine-tuning을 위해 BERT 모델은 먼저 pre-trained 된 파라미터로 초기화를 진행하고, 모든 파라미터들을 labeled data에 대해 task에 맞도록 fine-tuned 합니다. 각각의 task에 대해 동일한 pre-trained 매개변수를 사용하더라도 구분되는 fine-tuned model을 구성할 수 있습니다.
BERT의 독특한 특징 중 하나는 다양한 작업에 걸친 통합적인 아키텍처라는 점입니다. 각 Task에 맞게 fine-tuning된 모델들은 분명 pre-trained 된 아키텍처와 구분될만한 최소한의 차이를 가지게 됩니다.
Model Architecture
BERT 모델 아키텍처는 multi-layer bidirectional Transforcer encoder을 기반으로 합니다. Transformer의 성능이 뛰어나기 때문에 기존 연구의 구현과 거의 동일한 구조를 사용하며 따라서 트랜스포머 모델 아키텍처에 대한 자세한 배경 설명은 생략합니다.
본 연구에서는 트랜스포머의 블럭인 Layer의 수를 $L$로, hidden size 를 $H$로, self-attention head 수를 $A$로 표기합니다. 앞으로 2가지 모델에 대해 소개할 것인데, 각 모델들은 다음과 같은 파라미터 정보를 가집니다.
- $\text{BERT}_{\text{BASE}}$ : $L=12, H=768, A=12, \text{Total Parameters}=110M$
- $\text{BERT}_{\text{LARGE}}$ : $L=24, H=1024, A=16, \text{Total Parameters}=340M$
$\text{BERT}_{\text{BASE}}$는 비교 목적을 위해 OpenAI GPT와 동일한 모델 크기를 가지도록 설정되었습니다. 그러나 결정적으로 BERT 트랜스포머는 양방향 self-attention을 사용하는 반면 GPT 트랜스포머는 모든 토큰이 왼쪽의 context에 대해서만 attention할 수 있는 제한된 self-attention을 사용합니다.
Input/Output Representations
30,000개의 토큰 어휘와 함께 WordPiece 임베딩을 사용합니다. 모든 시퀸스의 첫번째 토큰은 항상 특수 분류 토큰인 [CLS] 입니다. 이 토큰에 해당하는 final hidden는 분류 작업을 위한 집계용 시퀸스 표현으로 사용됩니다. 문장 쌍은 단일 시퀸스로 함께 묶입니다. 이 때 2가지 방법으로 문장을 구분합니다.
- 특수 토큰 [SEP] 으로 구분
- 모든 토큰에 그것이 A 문장에 속하는지 B 문장에 속하는지를 나타내는 학습된 임베딩을 추가
그림에서 보듯 입력 임베딩을 $E$로, [CLS] 토큰의 final hidden state를 $C \in \mathbb{R}^H$로, i번째 입력 토큰에 의한 final hidden state vector를 $T_i \in \mathbb{R}^H$ 로 표기합니다.
특정 토큰에 대해 입력 표현은 해당 토큰, 세그먼트, 위치 임베딩을 합산하여 구성됩니다.
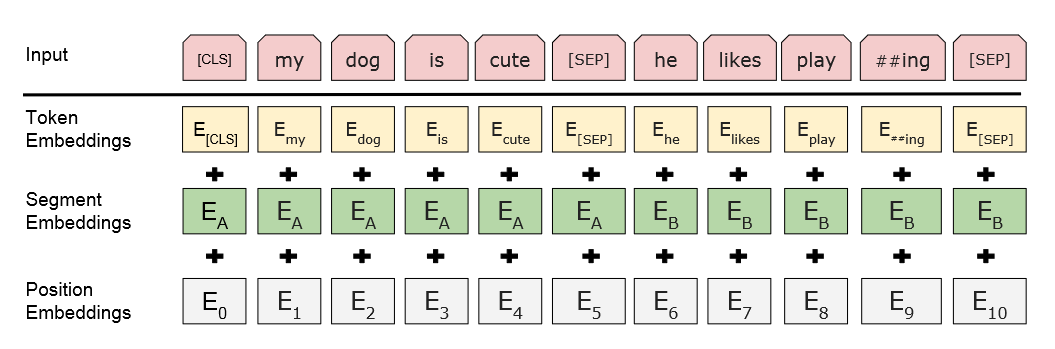
아래에서 나올 내용이지만 추가적으로 A,B에 대한 설명은 입력 문장이 1개가 아니라 2가지로 묶여 들어가고 그것이 A,B로 구분되는 것을 뜻합니다. 왜냐하면 정의했던 pre-task 가 문장의 전후 관계 예측이었기 때문에 그렇게 들어가는 것이고 즉 Segment Embeddings 는 추후 0이나 1 인 binary 로 구분을 하게 됩니다.
Pre-training BERT
2가지 비지도 학습을 사용해 BERT를 Pre-training 합니다.
Task #1 : Masked LM
심층적인 양방향 표현을 훈련시키기 위해 입력 토큰의 일부 비율을 무작위로 마스크한 다음 해당 마스크된 토큰을 예측하는 학습을 진행합니다. 이 작업을 MLM 이라 부릅니다. 이 경우 마스크 토큰에 해당하는 final hidden vector 는 표준 언어모델에서와 동일하게 어휘에 대한 출력 softmax에 들어갑니다. 모든 실험에서 각 시퀸스의 모든 WordPiece 토큰 중 15% 를 무작위로 마스킹했습니다. 기존 연구에서 전체 입력을 재구성하는 오토인코더 연구가 있었는데, BERT는 그게 아니라 마스크된 단어만 예측하는 작업을 수행합니다.
이를 통해 양방향에 대해 Pre-trained 된 모델을 얻을 수 있지만, Fine-tuning 과정에서 [MASK] 토큰이 나타나지 않기 때문에 pre-training 과정과 fine-tuning 과정에서 불일치가 발생한다는 단점이 있습니다. 이를 해결하기 위해 항상 마스크된 단어를 실제 [MASK] 토큰으로 대체하지는 않습니다. 학습 데이터 생성기는 예측을 위해 15%의 토큰 위치를 선택합니다. 만약 i번째 토큰이 선택되었다면 i번째 노큰을 (1) [MASK] 토큰으로 time의 80% (2) 랜덤 토큰으로 10% (3) 안 바꾸기 10% 로 대체합니다. $T_i$는 오리지널 토큰과 크로스 엔트로피 로스를 사용해 예측됩니다.
Task #2 : Next Sentence Prediction
QA나 NLI 같은 작업들은 두 문장 간의 관계에 대한 이해를 기반으로 합니다. 문장 간의 관계성을 학습시키기 위해 단일 언어 코퍼스에서 문장 예측 작업을 pre-training 합니다.
... 추후 추가 작성 예정
BERT 핵심 요약
< BERT 한문장 요약 >
The pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the art models for a wide range of tasks. → 자연어 처리 관련 작업을 할 거면, 잘 만들어 놓은 우리 모델을 large-scale 모델로 사용해라.
< BERT 특징 >
→ “masked language model” (MLM) pre-training objective 사용
→ 오토 인코더가 "자기 자신을 복원하도록" 학습했을 뿐인데, 특징 추출기의 역할을 했던 것처럼 BERT도 사전 에 정의한 목적에 맞게 학습
Unlike left-to-right language model pre-training, the MLM objective enables the representation to fuse the left and the right context. → 일반적인 RNN 모델과 다르게, 트랜스포머 구조를 채택하여 왼쪽 및 오른쪽의 context (문맥) 정보를 파악
< Pre-training 과정 >
① 복원 작업(오토 인코더와 유사)
→ 오토 인코더가 "자기 자신을 복원"하는 작업을 했던 것처럼, BERT도 무언가 작업을 수행하도록 해야 특징 추 출기의 역할을 할 수 있다.
→ 입력 문장에서 15%의 토큰을 [MASK] 처리하고, 이를 예측할 수 있도록 학습 진행
예시) "나는 어제 학교 식당에서 밥을 먹었다." → "나는 어제 학교 식당에서 [MASK] 먹었다."
정답으로 "밥을"을 예측할 수 있도록 학습 진행. 오토 인코더는 중간의 레이어를 "작게 (bottle-neck)" 만들어서 "압축"하도록 만들기 때문에 단순히 입력과 출력이 동일하도록 하면 됐음
→ 트랜스포머는? 입력과 출력이 기본적으로 같은 차원을 가짐. (bottle-neck이 없음) 그러므로, 입력에 노이즈를 씌운 뒤에, 그 노이즈를 걷어내도록 학습하는 것으로 이해 가능.
② 다음 문장인지 아닌지 예측 실제로 이어지는 문장 (50%), 그냥 서로 랜덤하게 붙인 문장 (50%)로 구성해서 → B가 A의 뒤에 있는 실제 문장이었는지 아닌지 예측하는 task를 동시에 학습
Reference: https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org