https://m.blog.naver.com/songsite123/223488533875
Song 전자공학 블로그 글 목록 / 사이트맵
기본적으로 네이버 블로그는 구글에 검색되지 않습니다. 구글 검색에 반영하기 위해서는 사이트맵을 만들고...
blog.naver.com
Machine unlearning 이란, 간단히 요약하자면 이미 학습된 모델에서 특정 데이터로 학습된 내역을 지우는 작업입니다. 본 논문의 그림은 아니지만 현재 kaggle 에서 열리고 있는 "NeurIPS 2023 - Machine Unlearning“ Competition의 그림을 인용하여 설명해보면 개념은 간단합니다.
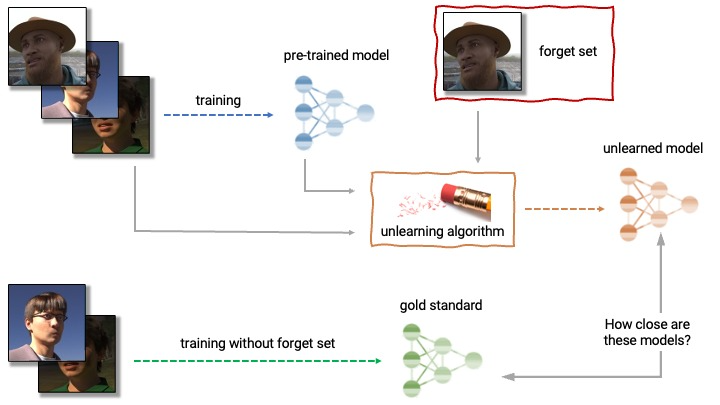
위처럼 3장의 이미지로 어떤 모델을 학습했다고 생각을 해봅시다. 그런데 알고보니 남의 사진을 허락도 없이 함부로 가져가서 사용해서 저작권 등의 이슈가 생긴 상황입니다. 어렵게 학습한 모델을 버리기가 너무 아쉬우니 어떻게 하면 "이미 학습한 모델을 특정 데이터가 없을 때 학습한 모델처럼 되돌릴 수 있을까?" 가 바로 Machine unlearning 입니다.
위 그림을 설명하면, 어떤 unlearning algorithm 으로 인해 pre-trained model을 바꾼 결과가, 지워야할 데이터를 제외한 나머지 데이터로 학습한 모델, 즉 training without forget set 으로 학습한 모델과 똑같이 만드는 것이 최종 목표가 되는겁니다.
아직까지 연구가 많이 진행되지 않은 딥러닝 분야의 최신 연구 주제입니다. 아직까지 저 데이터를 효과적으로 지우는 방법에 대해서는 연구가 되지 않았고, 바꾸는 방식도 Class unlearning 인지, Instance unlearning인지, unlearning algorithm을 만들 때 forget set만 가지고 unlearning을 하는지, retain set도 포함하여 unlearning을 하는지, 혹은 저렇게 만들어놓은 unlearning model 과 ground truth model(gold standard model)의 유사도를 어떻게 측정할 것인지에 대한 metric 등 앞으로 연구되어야 할 내용이 많은 주제입니다. 만약 이 분야의 연구가 성공적으로 진행된다면 개인 정보 이슈가 한참인 요즘 저작권 등의 문제를 해결할 수도 있을 것이고, adversarial example 들로 학습한 모델의 매개변수를 갱신하여 마치 adversiarl example을 학습한 적이 없는 상태로 만드는, 이러한 딥러닝 보안 분야에서도 활용할 수 있습니다.
현재까지의 연구 흐름을 간략히 요약하자면 지워야 할 데이터(forget set)만 가지고 모델을 수정하는게 가장 이상적이고 machine unlearning 의 취지와도 같습니다. 내가 100장을 사용해서 모델을 학습했는데, 1장만 지우고 싶은데 99장으로 다시 학습 시키는 건 간단히 생각해봐도 비효율적이잖아요? 그러니 1장을 사용해 모델을 수정하는게 이상적이지만 아직까지 연구 결과로는 지우고 싶은 1장, 즉 forget set 만으로는 효과적인 unlearning 이 어렵다. 라는 것이 결론이라 대부분의 연구들이 99장, retain set을 활용하는 방안을 주로 연구하고 있습니다. 오늘의 논문은 retain set으로 특정 클래스에 대한 변형 데이터를 통해 의도적으로 noise 를 증가(마치 adversarial attack) 하는 방법을 통해 Class unlearning 하는 내용을 소개합니다.
Abstract
Unlearning은 머신러닝 기반 응용 프로그램의 개인 정보 보호 및 보안을 강화하는데 있어 중추적인 역할을 할 수 있는 중요한 작업입니다. 저자들은 다음과 같은 질문을 제기합니다.
- 전체 학습 데이터를 사용하지 않고도 한 개, 혹은 다수의 클래스를 unlearning 할 수 있는가?
- unlearning process 를 빠르고 대규모의 데이터세트에 적용할 수 있도록 확장시키고, 이를 다양한 심층신경망에 대해 일반화할 수 있는가?
본 논문에서는 위 질문에 대한 효율적인 해결책을 제공하는 error-maximizing noise generation 과 impair-repair based weight manipulation 을 포함한 새로운 프레임워크를 소개합니다.
Original 모델을 사용하여 unlearn 해야 하는 클래스에 대해 노이즈 행렬(error-maximizaing noise matrix)이 학습됩니다. 노이즈 행렬은 우리가 지우고자 하는, unlearn 하고 싶어하는 target class에 대한 가중치를 조작하는 데 사용됩니다. 또한 네트워크 가중치 조작을 제어하기 위한 impair-repair step 을 소개합니다.
Impair step 에서는 노이즈 행렬과 매우 높은 learning rate 를 사용해서 sharp unlearning 을 유도합니다. 그 이후, repair step 을 통해 전체적인 성능을 다시 확보할 수 있습니다. 실험에서 Impair-repair step을 통해 매우 적은 update step에서도 전체 모델의 정확도를 상당히 유지시키면서, 우수한 학습 능력을 보여줍니다. 여러 개의 Class를 unlearning 하는 상황에 대해서도 단일 class를 unlearning 할때와 비슷한 update step을 가지므로 이러한 접근 방법은 더 큰 문제에 대해서도 확장 가능합니다. 우리의 방법은 기존 방법에 비해 상당히 효율적이며, 다중 클래스 unlearning 이 가능하며, 원래의 최적화 메커니즘이나 네트워크 디자인에 어떤 제약을 주지 않으며 소규모 및 대규모 비전 task 모두에서 잘 동작합니다. 이 연구는 심층 네트워크에서 unlearning을 빠르고 쉽게 구현하기 위한 중요한 step입니다.
Ⅰ. Introduction
이미 학습되어 있는 머신러닝 모델에서 단일 클래스 또는 여러 클래스에 속하는 데이터와 관련된 정보를 제거해야 하는 시나리오를 고려하겠습니다. 예를 들어, 회사는 이미 학습된 얼굴 인식 모델에서 사용자(또는 사용자의 집합)에 대한 특정 얼굴 이미지 데이터를 제거하도록 요청할 수 있습니다. 게다가 회사가 제거해달라고 요청한 얼굴 이미지에 직접 엑세스 할 수 없다는 제약 조건도 있는 상황입니다. 어떻게 이런 문제를 해결할 수 있을까요? 대중들의 개인 정보에 대한 인식이 증가함에 따라 , 그리고 머신러닝 기반 어플리케이션과 자신의 데이터를 공유할 때 발생하는 부정적인 영향을 인식함에 따라 이런 유형의 요구는 가까운 미래에 자주 제기될 수 있습니다. 개인 정보 보호 규정 또한 개인 정보 보호를 개인에게 제공하기 위해 향후 이러한 조항들을 포함할 가능성이 높아지고 있습니다.
기존의 법안들에 의해 기업들은 기본적으로 사용자 데이터를 수집할 수 있습니다. 그러나 사용자는 개인정보를 삭제할 권리와 개인정보의 판매를 거부할 권리를 가지고 있습니다. 회사가 머신러닝 모델을 훈련시키기 위해 사용자로부터 수집한 데이터(ex. 얼굴 데이터)를 이미 사용한 경우, 데이터 삭제 요청을 반영하여 모델을 적절하게 조작할 필요가 있습니다.
가장 단순한 해결 방법은 모든 요청들에 대해 모델에 대한 학습을 처음부터 다시 시작하는 것입니다. 그러나 이 방법은 막대한 시간과 자원을 소요합니다. 어떻게 이 프로세스를 더 효율적으로 만들 수 있을까요? 모델이 실제로 그러한 데이터 클래스를 학습하지 못했다는 것을 어떻게 알 수 있을까요? 모델의 전체 정확도에 미치는 영향을 최소화할 수 있는 방법은 무엇일까요?
선행 연구에서 제시된 unlearning(다른 이름으로 selective forgetting, data deletion, scrubbing 라고 부르기도 합니다.)의 솔루션들은 선형/로지스틱 회귀, 랜덤 포레스트, k-means clustering 등 간단한 학습 알고리즘에만 중점을 맞춥니다. 그러나 이러한 방법들은 간단하거나 소규모에 대한 문제에만 효과적이며, 심지어 계산 비용이 많이 듭니다.
CNN이나 비전 트랜스포머 같은 심층 네트워크에서의 효율적인 unlearning은 아직 해결해야하는 문제로 남아있습니다.특히 여러 개의 클래스에 대한 효율적인 unlearning 방법은 아직 연구되지 않았습니다. 이는 딥러닝 모델을 사용하는 동안 발생하는 여러 가지 복잡성 때문입니다. 예를 들어 CNN의 non-convex loss space는 최적화 궤적과 최종 네트워크 가중치 조합에 대한 데이터 샘플의 효과를 평가하기가 어렵습니다.
또한 동일한 네트워크에 대해서도 여러 가지 세트의 최적 가중치가 존재할 수 있으므로 얼마나 잘 잊었는가 하는 unlearning 정도를 확실하게 평가하기가 어렵습니다. Unlearning 을 통해 업데이트한 모델 가중치를 단순히 forget set만을 제외한 학습 데이터로 훈련한 모델과 비교하면 unlearning의 품질(정도)에 대한 유용한 정보가 나타나지 않을 수도 있습니다. 모델의 정확도를 유지하면서 데이터 코호트, 또는 전체 클래스의 데이터를 잊는 것은 기존 연구에서 볼 수 있듯이 사소한 문제가 아닙니다. 게다가 unlearning data 를 사용하지 않고 가중치를 효율적으로 조작하는 것 또한 여전히 해결되지 않은 문제로 남아있습니다. 여러 클래스에 대한 unlearning을 하는 것, 대규모 문제에 대해 unlearning을 하는 것, 다양한 딥 네트워크에 대해 솔루션을 일반화 하는 것은 모두 다른 task 입니다.
데이터 샘플 혹은 데이터 샘플의 클래스가 심층 네트워크 파라미터에 미치는 영향을 추정하는 것은 매우 어려운 문제입니다. 따라서 몇가지 unlearning reseach는 단순한 convex learning problem에 대한 분석에 초점을 맞추고 있습니다. 다른 연구에서 훈련 샘플의 렌즈를 통해 CNN 같은 블랙박스 모델의 행동을 연구하기 위한 influence function을 사용하였고, 이를 통해 training loss가 높은 데이터 포인트가 모델 파라미터에 더 영향력이 있음을 알아낼 수 있었습니다.
따라서 학습 이미지의 adversarial versions 는 그 이미지에 대한 loss를 최대화함으로써 생성됩니다. 또한 influence function은 데이터 포인터 그룹의 영향을 연구하는데 유용하다는 것을 알 수 있었습니다. 최근 다른 연구에서 딥러닝 모델에 대해 unlearning이 가능한 training example을 만들기 위해 error-minimizing noise 를 학습할 것을 제안했습니다. 이 아이디어는 이런 노이즈를 이미지 샘플에 추가함으로써 모델이 해당 샘플로부터 아무것도 학습할 수 없다고 속이는 것입니다. 이것을 학습에 사용하는 경우, 이런 이미지는 모델에 영향을 주지 않습니다.
Unlearning 은 데이터의 특정 클래스를 잊는 것 뿐만 아니라, 나머지 데이터를 잘 기억해야 합니다. 클래스 unlearning에 대해, 만약 모델이 원래의 훈련 당시 학습했던 패턴과 반대되는 패턴을 업데이트 할 수 있는 경우 이를 사용해 원하는 학습을 반영할 수 있습니다. 그리고 나머지 클래스 정보를 보존하는 것을 목표로 합니다. 우리는 원래 모델이 모든 클래스에 대해 loss를 최소화 하는 방법을 통해 학습된다는 것을 알고 있습니다. 따라서 직관적으로 unlearning class에 대해서만 모델의 loss와 관련된 노이즈를 최대화한다면, 이를 잊는데 도움이 되는 패턴을 학습할 수 있을 것입니다.
본 논문에서는 zero-glance privacy setting 에서 unlearning 하기 위한 프레임워크를 제안합니다. 즉 모델은 unlearning class의 데이터를 볼 수 없습니다. 우리는 unlearning class에 해당하는 영향력이 큰 포인트들로 구성된 error-maximizing noise matrix를 학습합니다. 이 후 네트워크 가중치를 업데이트 하기 위해 노이즈 행렬을 사용해 모델을 학습시킵니다. 본 논문에서는 단일/다중 클래스의 데이터를 unlearning 하는 방법인 Unlearning by Selective Impair and Repair(UNSIR)를 소개합니다. 이 방법은 사전 훈련된 딥러닝 모델에 적용하여 unlearning 을 수행할 수 있고, 요청된 클래스에 대한 정보를 unlearning 하는 것 뿐 아니라 원래 모델에 대한 정확도도 근접하게 유지할 수 있습니다. 즉 우리의 방법은 요청된 클래스의 unlearning과 나머지 클래스에 대한 정확도를 유지하는 것 모두에서 매우 우수합니다.
소규모 문제(10개의 클래스) 뿐만 아니라 대규모 비전 문제(100개의 클래스)에 대해서도 심층 네트워크에서 효율적인 멀티 클래스 unlearning을 달성한 최초의 방법입니다. 우리의 방법은 unlearning class의 데이터를 사용할 수 없는 엄격한 zero-glance setting 설정에서 수행됩니다. 이 설정이 실제 발생하는 real-word 적용을 할 수 있는 고유하면서도 실용적인 방법입니다. 중요하고 현실적인 언러닝의 활용 사례는 얼굴 인식입니다. 우리는 우리의 방법이 훈련된 모델이 언러닝 해야 하는 얼굴들에 대해 단일 얼굴뿐만 아니라 여러 얼굴을 매우 효율적인 방식으로 잊게 할 수 있음을 보여줍니다.
요약하자면, 우리의 핵심 기여는 다음과 같습니다.
- Zero-glance setting에서 Unlearning 문제를 소개
- Unlearning class에 대한 Error-maximizing noise를 학습. UNSIR은 매우 높은 학습률을 사용하여 single-pass에 대한 impair-repair 를 진행. impair 단계는 unlearning을 수행, repair 단계는 remaining class에 대한 정확도를 다시 복구하는 단계.
- 개별 클래스에 대한 순차적인 방법이 아닌 single-pass 로 멀티 클래스에 대한 unlearning 을 수행
- CNN, 비전 트랜스포머 등의 딥러닝 네트워크와 대규모 비전 데이터 세트에 대해 Unlearning 수행
Ⅱ. Related Work
A. Machine Unlearning
추후 업데이트 예정
B. Unlearning in Deep Neural Networks
추후 업데이트 예정
Ⅲ. Unlearning in Zero-Glance Privacy Setting
A. Zero-glace Privacy Assumptions
여러 사례에서 머신 러닝 모델은 얼굴 이미지나 개인적인 의료 데이터로 학습됩니다. 데이터의 민감한 특성과 통상적인 데이터 보호규정에서 정한 시간적인 규정 때문에 언러닝 목적으로도 잊고자 하는 데이터를 직접 사용할 수 없을 수도 있습니다. 그러나 우리는 사용자가 사전 훈련된 모델에 대해 즉각적으로 데이터를 삭제해달라는 요청을 언제든지 할 수 있다고 가정합니다. 이러한 상황에서는 오직 remaining data만 unlearning 에 사용할 수 있습니다. 또한 이런 작업을 통해 언러닝이 수행되면 모델에는 언러닝 데이터에 대한 정보가 없어야 합니다. 추후에 forgetting sample에 노출된 후에도 해당 표본을 실제로 언러닝 했는지 확인하려면, 재학습 시간이 상당히 길어야 합니다. (추가 설명 : 만약 제대로 언러닝이 되었다면 forget data에 대해 prediction를 하면 train data에서 보이는 양상이 아닌 test data에서 보이는 양상을 보여한다는 의미)
B. Preliminaries and Objective
우리는 언러닝 문제를 심층 네트워크에 대해 공식화 합니다. $n$개의 데이터 샘플과 $K$개의 클래스로 구성된 학습 데이터셋을 $\mathcal{D}_c = \{(x_i, y_i)\}^n_{i=1}$, 이 때 $x \in \chi \subset \mathbb{R}^d$는 입력이고 $y \in \mathcal{Y} = 1, \cdots , K$는 대응되는 클래스 라벨입니다. Forget class와 Retain class 들은 각각 $\mathcal{Y}_f$, $\mathcal{Y}_r$ 로 정의하며 $\mathcal{D}_f \cup \mathcal{D}_r = \mathcal{D}_c$ 이고, $ \mathcal{D}_f \cap \mathcal{D}_r = \emptyset$ 입니다. 전체 학습 데이터가 forget data + retain data 로 구성되어 있다는 것을 뜻합니다.
딥러닝 모델은 $f_\theta (x) : \mathcal{X} \to \mathcal{Y}$로 표현하고, $\theta \in \mathbf{R}^d$는 모델의 파라미터로 $\mathcal{X} \to \mathcal{Y}$에 사용됩니다. $f_\theta$는 원래의 완전한 훈련 데이터인 $\mathcal{D}_c$로 학습한 딥러닝 모델을 의미하며 $\theta$는 이 때의 가중치를 의미합니다. 위의 Forgetting in zero-glance setting 은 사전 훈련된 모델 $f$와 남은 데이터들의 retain 부분 집합 $\mathcal{D}_{r\_sub} \subset \mathcal{D}_r$ 을 사용한 새로운 가중치 $\theta_{\mathcal{D}_{r\_sub}}$를 뜻합니다. 이것은 $\mathcal{D}_f$에 대한 정보를 기억하지 못하고, 출력 공간에서 $\mathcal{D}_f$를 본 적이 없는 모델과 유사하게 동작합니다.
Unlearning을 수행하기 위해 사전 훈련 모델로부터 각각의 클래스 $\mathcal{Y}_i$에 대한 noise matrix $\mathcal{N}$을 학습합니다. 이 후 retain set $\mathcal{D}_r$로부터 샘플들을 분류하는 정확도를 유지하면서 forget set $\mathcal{D}_f$에서 샘플을 분류를 실패하게 만드는 방식으로 모델을 변환합니다. 이는 retain set $\mathcal{D}_r$의 부분 집합인 $ \mathcal{D}_{r\_sub}$를 사용함으로써 보장됩니다.
Ⅳ. Error-Maximizing Noise Based Unlearning
우리의 접근 방식은 unlearning class에 대한 모델 loss를 극대화 하는 noise matrix를 학습하는 것을 목표로 합니다. 이렇게 생성된 노이즈 샘플은 모델 업데이트 중에 해당 클래스에 대해 이전에 학습한 네트워크 가중치를 손상시키고, 덮어쓰면서 (damage/overwrite) 하면서 학습을 방해합니다. Error maximizing noise 는 언러닝 클래스에 대한 파라미트 업데이트를 활성화하는데 높은 영향력을 미칩니다.
A. Error-maximizing Noise
Error-maximizing noise $\mathcal{N}$ 를 모델의 입력과 똑같은 크기로 학습시킵니다. 목표는 $\mathcal{N}$과 unlearning 클래스 라벨과 $f : \mathcal{N} \to \mathcal{Y}_f, \mathcal{N} \neq \chi $ 상관관계를 만드는 것입니다. Error maximizing 과정에서는 pre-trained model의 가중치는 동결(변화X)시킵니다. 우리는 정규 분포 $N(0,1)$로 랜덤 초기화를 시킨 noise matrix $\mathcal{N}$이 주어지면, 다음 최적화 문제를 해결함으로써 error-maximizing noise를 최적화할 것을 제안합니다.
$$ \text{arg}\min_{\mathcal{N}}\mathbf{E}_{(\theta)}[-\mathcal{L}(f,y)+\lambda||w_{noise}||] $$
여기서 $\mathcal{L}(f,y)$는 unlearn 할 클래스에 대응되는 분류 loss이고 $f$는 학습된 모델을 나타냅니다. $w_{noise}$는 noise $\mathcal{N}$의 파라미터(이미지의 관점에서 픽셀 값으로 해석 가능)이며 $\lambda$는 두 항 간의 trade-off를 관리하는데 사용됩니다. 최적화 문제는 모델의 분류 loss를 극대화하는 $L_p$-norm bounded noise 를 찾습니다. 본 논문의 방법에서는 크로스 엔트로피 loss function $\mathcal{L}$이랑 $L_2$ normalization을 사용합니다.
Noise가 $\mathcal{D}_f$가 나타내는 것과 반대가 되도록 forget class에 대응되는 error를 최대화합니다. UNSIR 알고리즘의 impair stage에서 이를 사용하면 $\mathcal{D}_f$와 관련된 정보가 삭제됩니다. 전반적으로 이는 딥 네트워크에서 효율적인 언러닝을 가능하게 합니다. 위 수식의 두 번째 항 $\lambda||w_{noise}||$는 $\mathcal{N}$의 값이 너무 커지는 것을 방지하여 전반적인 loss를 정규화합니다. 이러한 $\mathcal{N}$의 정규화가 없다면 모델은 더 높은 값을 가진 이미지가 unlearning class에 속한다고 믿기 시작할 것입니다. 멀티 클래스의 데이터에 대해서는 noise matrix $\mathcal{N}$을 각 클래스 별로 별도로 학습합니다. 최적화는 모델의 loss에 대한 noise matrix를 이용하여 수행되기 때문에 이는 무시할 정도의 시간에 이루어질 수 있습니다. UNSIR 알고리즘은 단일 클래스와 멀티 클래스 언러닝 모두에 대해서 한 번만 실행됩니다.
B. UNSIR: Unlearning with Single Pass Impair and Repair
$\mathcal{D}_{r\_sub}$와 noise matrix를 결합하여 (i.e.. $\mathcal{D}_{r\_sub} \cup \mathcal{N})$ unlearning을 유도하기 위해 1 epoch 동안 모델을 학습(impair) 합니다. 그 후 다시 1 epoch 동안 $\mathcal{D}_{r\_sub}$에 대해서만 모델을 학습(repair)합니다. 최종 모델은 언러닝 목표 클래스에 대해 언러닝을 수행하고 나머지 클래스의 정확도를 유지하는 데 탁월한 성능을 보입니다.
Impair.
생성한 노이즈도 포함한 원래 분포의 작은 부분집합에 대해 모델을 훈련합니다. 이 단계는 네트워크에서 forget class에 대한 데이터 인식을 담당하는 가중치를 손상시키기 때문에 impair 라고 부릅니다. 항상 높은 learning rate를 사용하고 단일 epoch 의 impair 만으로도 대부분 충분하다는 것을 확인했습니다.
Repair.
impair step은 때때로 retain class에 대한 예측하는 역할을 하는 가중치를 방해할 수도 있습니다. 따라서 retain data $\mathcal{D}_{r\_sub}$에 대한 단일 epoch(낮은 확률로 더 많은 epoch가 필요할 수도 있음)동안 모델을 훈련시켜 이러한 가중치를 복구합니다. 최종 업데이트된 모델은 forget sample에 대한 재학습 시간이 오래걸립니다. 즉 네트워크가 forget sample을 재학습하는데 상당한 수의 epoch가 소요된다는 것이고 이는 효과적인 unlearning을 위한 중요한 기준 중 하나이며 제안된 방법입니다.
Unlearning algorithm의 전체적인 프레임워크는 아래의 Figure 1과 같습니다.

Ⅴ. Experiments And Results



