이번 논문은 모바일 또는 임베디드 같은 소형 컴퓨터에서 사용할 수 있도록 경량화된 모델인 MobileNetV1 을 소개합니다. 어떻게 경량화했는가? 가 핵심 아이디어인데, Depthwise separable convolution 을 사용하여 모델의 성능을 크게 줄이지 않으면서 크게 경량화 시킨 논문입니다.
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Abstract
본 논문에서는 모바일 및 임베디드 비전 어플리케이션을 위한 MobileNets 라는 효율적인 모델 클래스를 제안합니다. MobileNets는 depth-wise separable convolution을 사용해 신경망을 구축한 간소화된 아키텍처를 기반으로 합니다. latency와 accuracy 사이의 trade-off 를 맞추는 두 가지 간단한 하이퍼 파라미터를 소개할 것이며, 이 하이퍼파라미터를 통해 어플리케이션에 적합한 크기의 모델을 선택할 수 있습니다. 수많은 실험을 통해 좋은 성능을 보이는 설정을 찾았으며, 이는 다른 모델들에 비해 성능이 거의 유지되면서도 크기는 몇 배 줄인 모델들입니다.
MobileNet 을 통해 이러한 다양한 비전 task에 적용할 수 있다는 걸 말해줍니다. 5년정도 된 논문이라 그런지 핸드폰도 좀 옛날 느낌? 이 나네요.
1. Introduction
해당 논문은 2017년에 나온 논문인데, 이 당시에는 AlexNet을 시작으로 GoogleNet, VGGNet, ResNet 등 더 높은 정확도를 달성하기 위해 깊고 복잡한 CNN 네트워크를 만드는 것이 추세였습니다. 근데 이렇게 되면 모델의 크기가 너무 커지고 가성비가 안좋아진다는 내용을 언급합니다. 정확도만 높이는 것이 능사가 아니고 효율적으로 만드는 것이 중요하다 !
따라서 모델의 크기와 성능을 적절히 선택할 수 있도록 하는 2개의 하이퍼 파라미터를 가지는 모델을 제시합니다. 2절에서는 지금까지의 경량화된 모델들, 3절에서는 MobileNet을, 4절에서는 실험, 5절에서는 결론을 요약합니다.
2. Prior Work
최근(해당 논문 발표 당시)의 모델 경량화 연구는 크게 2가지로 나뉩니다.
- Pretrained Network 압축
- 소규모 네트워크를 직접 학습
이 밖에도 다양한 사전 연구들을 소개합니다. 해싱, 양자화, pruning, low bit networks, 허프만 코딩 등등...
소규모 네트워크에 대해 다룬 기존 연구들은 크기에만 초점을 맞추고 속도는 고려하지 않는 문제들이 있는데, MobileNet에서는 리소스 제한(latency, size)에 맞는 소규모 네트워크를 구체적으로 선택할 수 있는 네트워크 아키텍처 클래스를 제안합니다. MoblieNet은 기본적으로 소규모 모델이지만 latency를 최적화하는데 초점을 맞춥니다.
3. MobileNet Architecture
이번 절에서는 depth-wise separable conv 를 사용한 핵심 레이어를 설명하고 네트워크 구조, 두 개의 하이퍼파라미터 width multiplier랑 resolution multiplier에 대해 설명합니다.
3.1 Depthwise Separable Convolution
Depthwise separable convolution이란, standard 컨볼루션을 쪼갠 컨볼루션입니다. 일반적인 컨볼루션을
- Depth-wise convolution (dwConv)
- Point-wise convolution (pwConv, $1\times 1$ conv)
로 Factorized 한 것을 말합니다.
Depth-wise conv 는 각 입력 채널마다 단일, 1개의 필터를 적용하는 역할입니다. Point-wise conv는 dwconv의 결과를 합치기 위해 $1 \times 1$ conv를 적용합니다. 이와 비교해서 일반적인 컨볼루션은 이 2개의 step 이 하나로 합쳐진 것이라고 보시면 됩니다. 논문의 자료만으로 이해가 어려울 수 있어 외부 자료를 참고하겠습니다.
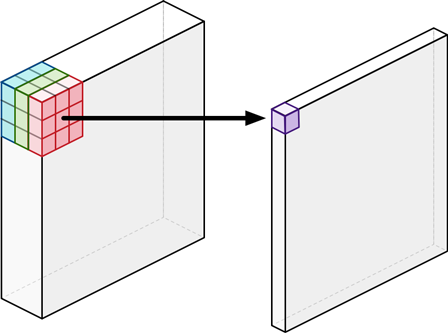
위 사진은 일반적인 CNN의 예시입니다. 입력 이미지가 3의 depth를 가지고 있고, 우리가 $3\times 3 \times 3$ 필터를 사용하면 하나의 값으로 연산됩니다. 이 때 저 fileter의 파라미터 수는 $ 3 \times 3 \times 3 = 27$ 이 됩니다. 이 작업을 한 가지 step으로 보지 말고, 2번으로 쪼개볼까? 가 이 논문의 핵심 아이디어입니다.
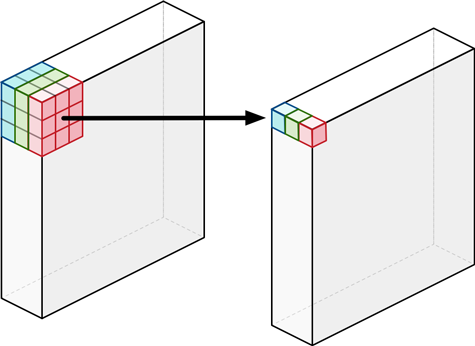
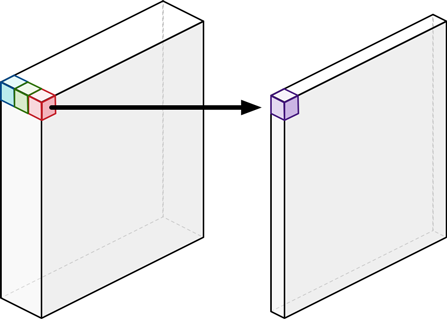
먼저 파란색, 초록색, 빨간색처럼 입력의 각 depth 마다 (depth-wise) $3\times 3$ 필터를 적용하여 값을 뽑아내자는 겁니다. 그러면 우리는 $1\times 3 \times 3$ 를 3번 사용하여 1개의 값을 총 3개 뽑아냅니다. 이것이 dwConv 입니다.
dwConv에 필요한 파라미터 수를 생각해보면 $1\times 3 \times 3$ 필터가 3개 필요한데, 따라서 필요한 파라미터의 수는 $9 * 3 = 27$ 입니다. 여기서 헷갈리면 안되는게 이 때 적용하는 $1\times 3 \times 3$ 는 서로 다른 필터 3개를 사용하는 것입니다.
그러면 우리는 지금 중간의 3개의 값을 하나의 값으로 합쳐준다면? 결론적으로 위의 일반적인 컨볼루션과 동일한 입력과 출력을 얻게 됩니다. 중간 3개의 값에 $1\times 1$ 컨볼루션을 적용하여 하나의 값을 얻어내는 것이죠. 이것이 point-wise 컨볼루션입니다. 입력 채널이 3이므로 실제 pwConv 필터 크기는 $ 3\times 1 \times 1$이 될 것입니다.
위 과정을 생각해보면 필요한 파라미터가 $ 27 \to 30 $ 로 오히려 늘어난 것 같습니다. 그런데 왜 이게 경량화가 되는가? 라고 생각해보면, 지금은 출력 차원의 depth 를 1로 생각한 예시이기 때문입니다.
만약에 위와 동일한 예시에서 출력차원의 depth 가 $4$이라고 생각해보겠습니다. 즉 맨 처음의 $3\times 3\times 3$ 필터를 4개 사용하는 것이겠죠? 그렇다면 일반적인 컨볼루션에서 필요한 총 파라미터 수는 $3 \times 3 \times 3 \times 4 = 81$ 이 됩니다.
이 작업을 dwConv와 pwConv로 나누어 수행한다면, 먼저 $1\times 3\times 3$ 필터가 입력 depth의 개수인 3개가 필요할 것입니다. 그러니 여기서 필요한 파라미터는 $ 3\times 3\times 3 = 27$이 됩니다.
pwConv는 $1\times1$ 필터를 사용해 채널 간의 정보를 결합하죠. 근데 이 때 입력차원의 크기가 3이므로 실제 필터의 크기는 $3\times 1\times 1$이 될 것입니다. 출력 차원이 4이므로 이런 $3\times 1\times 1$ 필터가 4개 필요합니다. 따라서 필요한 파라미터의 수는 $3\times 1\times 1 \times 4 = 12$ 입니다.
이렇게 출력 차원의 depth가 1이 아닌 경우, 당장 4인 경우만 봤는데도 파라미터수가 $81 \to 27 + 12 = 39$ 로 절반 이하로 줄어듭니다.
이 간단한 아이디어로 MobileNet은 경량화를 수행합니다. 입력 채널의 수 $C_{in}$, 출력 채널의 수 $C_{out}$, 각 필터의 크기 $K\times K$라고 놓고 이를 일반화 하면 다음과 같습니다.
- Standard Convolution : $ C_{in}\times K\times K\times C_{out}$
- Depthwise saparable convolution $ \to C_{in} \times K \times K + C_{in} \times C_{out}$
- Depth-wise conv : $C_{in} \times K \times K$
- Point-wise conv : $C_{in} \times 1 \times 1 \times C_{out}$
즉 3차원 계산을 두 방향으로 먼저 계산한 후 나머지를 계산하는 방식으로 연산하면 연산량을 줄일 수 있다는 것입니다. 논문에서는 쓸데 없이 어렵게 나와있어서 좀 쉽게 예시를 들어봤습니다. 결론적으로 이 연산을 사용하면 거의 커널 사이즈의 제곱에 반비례할 정도로 파라미터가 줄어듭니다. 만약 필터를 $3\times 3$ 을 쓴다면 거의 8~9배 정도로 연산이 줄어드는 효과가 있습니다.
3.2 Network Structure and Training
표준 Conv와 DS Conv Layer의 구조를 비교하면 다음과 같습니다.

이 구조를 코드로 짜는 것도 너무 간단합니다. PyTorch 로 구현한 오른쪽 Block의 코드를 한 번 보겠습니다.
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
self.stride = stride
self.in_planes = in_planes
self.out_planes = out_planes
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
핵심이라고 할만한 부분은 groups 인자에 입력 채널 수를 전달하여, 입력 채널 수 만큼의 그룹을 만들어 각 채널에 대해 독립적인 컨볼루션을 수행하는 부분입니다. depth-wise conv에서 패딩이 1인 이유는 차원(너비와 높이)을 유지하기 위함입니다.
MobileNet은 첫 번째 Layer를 Full conv로 사용하는 것을 제외하면 모두 위 Block을 이용한 DSConv를 사용합니다. MobileNet 모델의 구조는 다음과 같습니다.
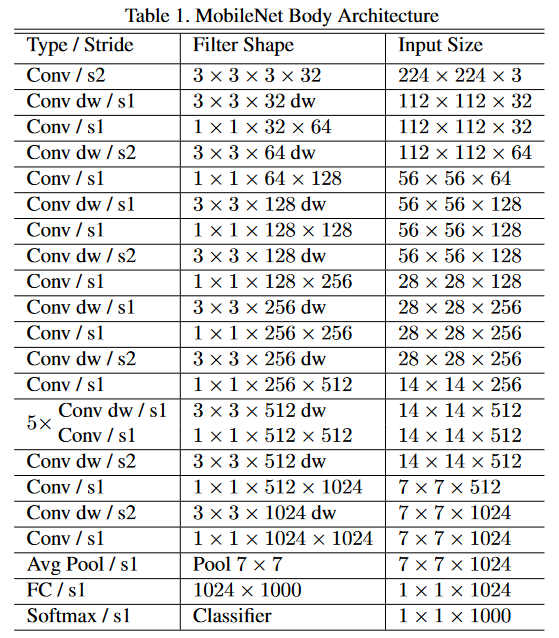

이것도 복잡해보이지만, 실제 블록만 보면 정말 간단한 코드입니다. 총 13개의 Block을 가지는 것이죠. 코드도 아주 간단합니다.
class MobileNet(nn.Module):
cfg = [64, (128,2), 128, (256,2), 256, (512,2), 512, 512, 512, 512, 512, (1024,2), 1024]
def __init__(self, num_classes=10):
super(MobileNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x if isinstance(x, int) else x[0]
stride = 1 if isinstance(x, int) else x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
위의 Block 코드를 통해 이렇게 짧은 코드만으로 모바일 넷을 구성할 수 있습니다.
실제 실험에서는 RMSProp으로 진행했다고 합니다. 그리고 DSConv에는 파라미터가 별로 없어서 weight decay는 거의 또는 전혀 사용하지 않는게 낫다고 나와있습니다.
그런데 이건 저는 동의하지 못하는게, 제가 모바일넷을 최적화시키는 프로젝트를 했었는데 그 때는 또 weight decay를 추가한 게 성능이 더 잘나왔습니다. 그러니 이건 상황에 맞게... 파라미터가 더 적다는 것만 알고 있으면 될 것 같습니다.
3.3 Width Multiplier: Thinner Models
이미 충분히 작은 모델이지만 더 경량화 시키고 더 빠르게 만들어야 하는 경우가 있습니다. Width multiplier 라고 부르는 하이퍼 파라미터 $\alpha$는 각 layer마다 얼마나 더 얇게 만드는지를 결정합니다. 입출력 채널 수가 $M, N$에서 $\alpha M, \alpha N$이 됩니다. 이 때 $\alpha \in (0, 1]$이고, 이 값을 통해 경량화를 조절할 수 있으며 디폴트 값은 1입니다.
3.4 Resolution Multiplier: Reduced Representation
두 번째로는 resolution multiplier $\rho$ 입니다. 이는 해상도와 관련된 파라미터로 입력 이미지와 각 내부 레이어의 표현 전부 이 하이퍼 파라미터를 통해 곱해 줄입니다. $\alpha$와 비슷하게 $\rho \in (0, 1]$ 이고, 이미지 해상도를 조절하는 것에 쓰입니다. 계산량은 $\rho ^2$에 비례하여 줄어듭니다.
4. Experiments
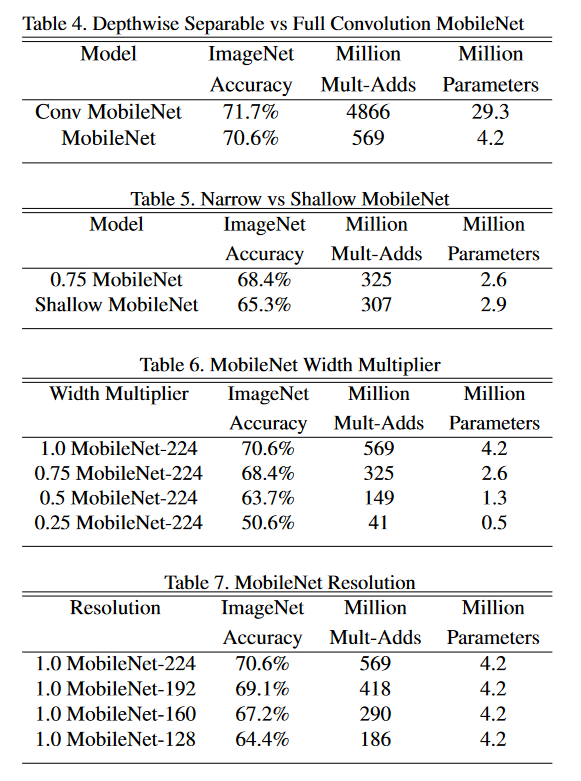
5. Conclusion
Depthwise Separable conv 를 사용한 경량화 모델 MobileNet을 제안했으며, 모델 크기나 연산량에 비해 성능이 크게 떨어지지 않고 시스템의 환경에 따라 적절한 크기의 모델을 선택할 수 있도록 하는 여러 옵션(multipier)를 제공합니다.
Reference : https://arxiv.org/abs/1704.04861
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. We introduce tw
arxiv.org
https://machinethink.net/blog/googles-mobile-net-architecture-on-iphone/