AI의 응용분야 중 다양한 접목 시도를 하고 있는 분야로 의료분야가 있습니다. 오늘의 논문은 LLM을 어떻게 의료 현장에서 사용하는지에 대한 응용, 원리, 해결해야 하는 과제 등을 전체적으로 다룬 리뷰 논문입니다.
전반적인 내용을 다루는 만큼 목차가 길기 때문에 원하는 부분에 대해 하이퍼 링크 부분을 참고해주시면 되겠습니다.
2. The Principles of Medical Large Language Models
3. Biomedical NLP Tasks
4. Clinical Applications
4.1 Medical Diagnosis
4.2 Formatting and ICD-Coding
4.3 Clinical Report Generation
4.4 Medical Education
4.5 Medical Robotics
4.6 Medical Language Translation
4.7 Mental Health Support
5. Challenges
5.1 Hallucination
5.2 Lack of Evaluation Benchmarks and Metrics
5.3 Domain Data Limitations
5.4 New Knowledge Adaptation
5.5 Behavior Alignment
5.6 Ethical, Legal and Safety Concerns
6. Future Directions
6.1 Introduction of New Benchmarks
6.2 Interdisciplinary Collaborations
6.3 Multimodal LLM Integrated with Time-Series, Visual, and Audio Data
6.4 Medical Agents
7. Conclusion
A Survey of Large Language Models in Medicine: Principles, Applications, and Challenges
Abstract
ChatGPT 같은 대규모 언어모델(LLM)들은 자연어 이해 및 생성 기능으로 상당한 주목을 받고 있습니다. 이를 의사와 환자 치료를 지원하기 위해 의학에 적용시키는 것이 유망한 연구분야로 떠오르고 있습니다. 이러한 추세를 반영하기 위해 본 논문은 의료 LLM이 직면한 원칙, 적용 및 과제에 대한 포괄적인 개요를 제공합니다. 구체적으로 다음과 같은 질문을 해결하고 논의하는 것에 대해 다룹니다.
- 의료 LLM을 어떻게 구축할 수 있을까?
- 의료 LLM의 다운스트림 성과는 어떠한가?
- 의료 LLM이 실제 임상 현장에서 어덯게 적용될 수 있는가?
- 의료 LLM 사용으로 인해 발생하는 문제, 어려움은 무엇인가?
- 의료 LLM을 어떻게 더 잘 구성하고 활용할 수 있는가?
이 밖에도 정기적으로 업데이트 되는 의료 LLM에 대한 실질적인 가이드 목록은 아래 주소에서 확인할 수 있습니다.
GitHub - AI-in-Health/MedLLMsPracticalGuide: A curated list of practical guide resources of Medical LLMs (Medical LLMs Tree, Tab
A curated list of practical guide resources of Medical LLMs (Medical LLMs Tree, Tables, and Papers) - GitHub - AI-in-Health/MedLLMsPracticalGuide: A curated list of practical guide resources of Med...
github.com
1. Introduction
많은 사전연구들로 다양한 LLM들이 구성이 되었고 실제로 유망한 결과를 얻어냈지만 개발 및 적용에는 해결해야 할 몇 가지 주요 문제들이 존재합니다. 첫째로 이러한 모델들 중 다수는 주로 대화 및 QA 같은 생물의학 NLP 작업에 중점을 두며 종종 임상에서의 실제 유용성을 간과합니다. 최근 연구들에서는 이 같은 NLP 모델을 전자 건강 기록(EHR), 퇴원 요약 생성, 치료 계획 등을 포함한 다양한 임상 시나리오에서 의료 LLM의 잠재력을 탐색하고 있습니다. 그러나 이는 주로 사례 연구를 수행하고, 임상의를 초대하여 소수의 샘플에 대한 인간 평가를 진행하기 때문에 평가를 위한 표준 데이터 세트가 부족합니다(라벨링 비용도 비싸다. 아무나 못하는 작업이기 때문이다). 두 번째로 기존의 의료 LLM들은 텍스트 요약, 관계 추출, 정보 검색 및 텍스트 생성 같은 작업을 뭇하고 주로 의료 질문 답변을 중심으로 평가를 진행합니다.

따라서 좀 더 포괄적인 적용을 위해 위의 outline 을 기준으로 의료 LLM이 무엇인지, 어떻게 효과적으로 구축할 수 있는지, 현재의 평가 방식, 실제 임상 환경 적용, 해결해야하는 과제, 최적화 등에 대해 다룹니다.
2. The Principles of Medical Large Language Models
의학 분야에서 LLM을 접목시키는 것에 대한 연구가 많아지고 있습니다. 이 섹션에서는 명확성을 위해 의료 LLM의 원리를 요약하고 배경에 대한 소개를 제공하는 것에 중점을 둡니다. 기존의 의료 LLM은 주로 처음부터 Pre-trained 되고 task에 맞게 fine-tuning 하거나, 의료 도메인에 맞게 자체적으로 prompting 합니다. 따라서 Pre-train, Fine-tuning, Prompting 3가지 방법 측면에 대해 의료 LLM의 원칙에 대해 소개합니다.
2.1 Pre-training
의료 LLM의 Pre-training에 사용되는 데이터는 구조화된 텍스트도 있고, 그렇지 않은 텍스트들도 있습니다. 이를 모두 포함하는 대규모 의학 텍스트에 대해 LLM이 학습됩니다. 예를 들어 EHR, DNA 서열, 의학 문헌, 임상 기록 등이 포함될 수 있습니다. 이 중에서 PubMed, MIMIC-III clinical notes, PMC literature 은 의료 LLM의 Pre-training에 널리 사용되는 3개의 의료 코퍼스입니다.
이를 사용해 학습된 대표적인 모델들을 예로 들어보면
- PubMedBERT : PubMed 로 사전학습
- ClinicalBERT : MIMIC-III 로 사전학습
- BioBERT : PubMed 랑 PMC로 사전학습
- MEDITRON : Clinical Practie Guidelines(CPGs) 로 추가 사전학습
등 이 존재합니다. 이런 LLM들은 의료 종사자와 환자가 진단, 치료 및 관리에 대한 결정을 내릴 수 있도록 도움을 주는 역할입니다.
의료 LLM의 Pre-train 목표는 일반적으로 사용되는 masked language의 모델링, 의료 영역의 요구 사항에 맞게 개선된 다음 문장 예측이 포함됩니다. Pre-train 된 LLM은 일반적으로 다양한 다운스트림 작업에 대해 Fine-tuning 하여 평가가 진행됩니다. 현재 의료 LLM을 평가하기 위해 널리 사용되는 다운스트림 작업은 QA와 NER이며, 모델이 질문에 대한 응답/답변을 생성하는 것에 대해 평가를 진행합니다. 학습에 사용되었던 의학 지식을 추출하는 것은 진단 지원 및 의학 연구 같은 응용 분야에서 매우 중요합니다.
두 개의 벤치마크 BLUE랑 BLURB는 모델의 표준 평가를 위해 널리 사용하여 NER 성능, 관계 추출, 문서 분류, 유사성 및 추론 성능을 평가합니다. BLURB(Biomedical Language Understanding & Reasoning Behcnmark)는 BLUE 보다 더 포괄적인 벤치마크입니다.
2.2 Fine-tuning
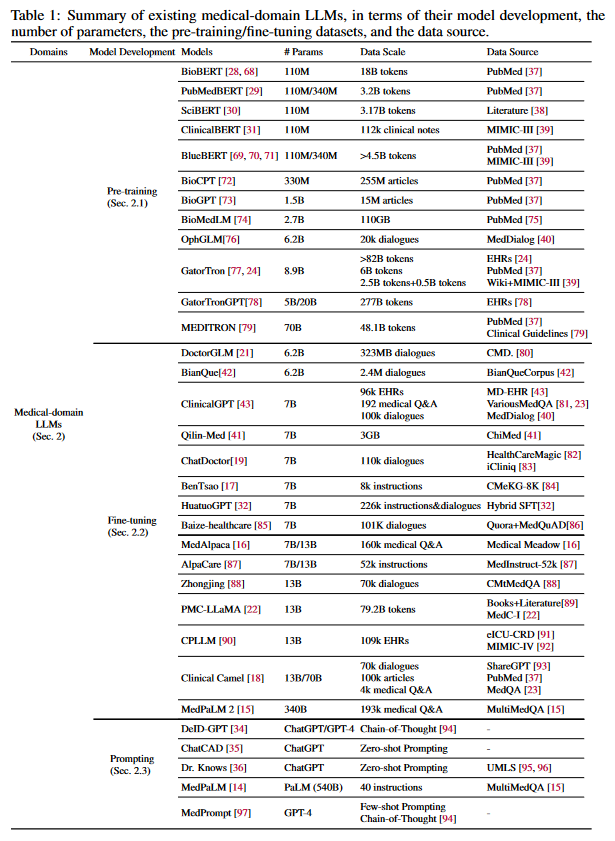
처음부터 LLM을 학습하려면 많은 연산 능력, 비용 및 시간이 필요합니다. 따라서 많은 사전 연구에서 일반 LLM을 의료 데이터로 Fine-tuning하여 도메인 별 의학 지식을 학습해 의료 LLM을 획득하는 방법을 제안하고 있습니다. 현재 널리 사용되는 Fine-tuning 방법으로는 SFT(Supervised Fine-Tuning), IFT(Instruction Fine-tuning), LoRA(Low-Rank Adaptation), Prefix Tuning 등이 있습니다. Fine-tuning된 의료 LLM들이 표 1에 요약되어 있습니다.
Supervised Fine-Tuning (SFT)
SFT는 의사-환자 대화, 의학적 질의응답, 지식 그래프 등의 고품질 의료 코퍼스를 활용하는 것을 목표로 합니다. 구성된 SFT 데이터는 동일한 훈련 목표(예를 들어 다음 토큰 예측)을 사용해 일반적인 LLM을 추가로 Fine-tuning 하기 위한 훈련 데이터로 사용합니다. 따라서 SFT는 일반 LLM이 풍부한 의료 도메인을 학습하고 의료 영역에 맞춘 전문 의료 LLM으로 전환할 수 있도록 추가적인 fine-tuning 단계를 제공합니다.
SFT의 다양성은 다양한 유형에 대한 학습을 통해 의료 LLM 개발을 가능하게 합니다.
- DoctorGLM : ChatGLM 을 SFM
- ChatDoctor : LLaMA 를 SFM
- MedAlpaca : 16만 쌍의 의료 Q&A 를 통해 SFM
- Clinicalcamel : LLaMa-2 모델을 SFM
- Qilin-Med / Zhongjing : Baichuan / LLaMA에 대해 지식 그래프를 추가적으로 통합하여 SFM
전반적으로 기존 연구에서 의료 도메인에 대해 LLM의 성능을 향상시키는데 SFT가 효과가 좋다는 것이 입증되었습니다. 이는 SFT가 모델의 능력뿐 아니라 정확한 임상 결정 지원을 제공하는 능력 또한 향상시킨다는 것을 보여줍니다.
Instruction Fine-Tuning (IFT)
IFT란 우선 일반적으로 명령어-입력-출력(instruction-input-output) 으로 구성된 명령어 기반 교육 데이터 세트를 구성합니다. IFT의 주 목표는 LLM을 추가로 학습시켜 다양한 인간/작업 지침을 따르고 출력을 의료 도메인에 맞춰 전문적인 의료 LLM의 생성 능력을 향상시키는 것입니다. SFT와 IFT의 주요 차이점은 SFT는 pre-training을 통해 LLM에 의학 지식을 주입하여 의료 텍스트를 이해하고 다음 토큰을 정확하게 예측하는 능력을 향상시키는 것에 중점을 두는 반면, IFT는 다음 토큰을 정확하게 예측하는 것이 아니라 모델의 instruction following 능력을 향상시키고, 주어진 instruction과 일치하도록 출력을 조정하는 것을 목표로 합니다. 결과적으로 SFT는 의료 LLM의 성능 향상을 위해 훈련 데이터의 양을 강조하는 반면 IFT는 양보다는 데이터의 질과 다양성을 더 강조합니다. 즉 IFT를 통해 LLM의 성능을 향상시켜려면 IFT 데이터의 품질이 높고 광범위한 의료 지침과 광범위한 의료 시나리오를 포함하는지 확인하는 것이 더 중요합니다. 이러한 다양성이 곧 다양한 의료 지침 및 상황을 이해하는 데 필수적이기 때문입니다.
이를 위해 IFT를 사용한 모델들은 여러 방법을 씁니다.
- MedPaLM-2 : PaLM을 fine-tuning 하기 위한 데이터를 구성하기 위해 자격을 갖춘 의료 전문가가 데이터 구성
- ChatGLM-Med : 지식 그래프(knowledge graph)를 기반으로 knowledge-based instruction data 구성
- Zhongjing : IFT를 수행하기 위한 명령어 데이터로 multi-turn dialogue 를 추가
- MedAIpaca : 의료 대화와 의료 Q&A 쌍을 동시에 통합
IFT는 효과적으로 다운스트림 성능을 향상시키는 것으로 입증되었습니다. IFT와 SFT는 다양한 측면에서 성능을 향상시키는데 사용될 수 있으므로 IFT와 SFT를 결합하여 보다 강력한 의료 LLM을 얻으려는 최근 연구가 진행되고 있습니다.
Parameter-Efficient Tuning
Efficient Tuning은 LLM fine-tuning을 위한 계산 및 메모리 요구 사항을 크게 줄이는 것을 목표로 합니다. 핵심 아이디어는 LLM에서 가장 작은 매개변수 subset만 fine tuning하여 pre trained된 LLM의 대부분의 매개변수를 변경하지 말고 유지시키는 것입니다. 일반적으로 사용되는 Parameter-efficient tuning 기법에는 LoRA, prefix tuning, Adapter Tuning이 있습니다.
LoRA
Full-rank 가중치 행렬을 모두 Fine-tuning 하는 것과 달리 LoRA는 원래 LLM의 매개변수를 보존하고, 각 Transformer 계층의 self-attention 모듈에 학습이 가능한 low-rank 행렬을 추가합니다. 이렇게 하는 이유는 LoRA 논문 원문에 나온 말을 인용해보면
- "The learned over-parameterized models in fack reside onn a low intrinsic dimension"
- "there exists a low dimension reparameterization that is as effective for fine-tuning as the full parameter space"
즉, 모델이 복잡하더라도 실제로 중요한 정보를 포함하고 있는 차원은 상대적으로 낮다. 라는 가정을 세웁니다.
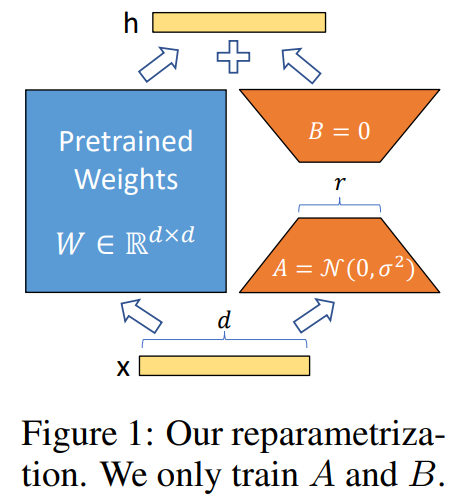
따라서 위에서 언급한 것처럼 1) Freeze pretrained weights, 2) Insert rank decomposition matrices, 3) Train A, B 의 스텝으로 매우 효과적으로 LLM을 Fine-tuning 할 수 있는 방법을 소개하는 논문입니다.
Prefix Tuning
대규모 언어 모델을 특정 작업이나 도메인에 맞게 조정하는 방법 중 하나로, 전체 모델을 재학습시키는 것이 아닌 모델의 일부분만을 조정하여 특정 작업에 맞게 최적화합니다. 모델의 입력부에 "prefix"라 불리는 작은 신경망을 추가합니다. 이 prefix는 모델에 입력되는 각 시퀸스 앞에 고정된 길이의 토큰 시퀸스로 존재하고, 이 토큰들이 특정 작업에 대해 모델의 반응을 조절하는 역할을 합니다. prefix는 모델과 함께 학습되며, 이 과정에서 모델의 주요 파라미터는 변경되지 않고 오직 prefix 부분만이 조정됩니다.
Adapter Tuning
모델 전체 재학습 대신, 모델 내에 어댑터(adapter) 모듈을 삽입하고 이를 특정 task에 대해 학습시키는 방법입니다. 어뎁터 모듈은 모델의 각 레이어 사이에 추가되는 작은 신경망으로, 이를 통해 pre-train된 모델의 핵심 파라미터는 고정되어 있는 상태에서 어뎁터 모듈만 학습시키는 방식을 뜻합니다.
요약해서 Parameter-Efficient Tuning은 특정 도메인에 대한 LLM을 개발하거나 어떤 고유한 요구 사항을 충족시키기를 원할 때 유용합니다. 성능을 저하시키지 않으면서 계산 요구량을 크게 줄일 수 있습니다.
2.3 Prompting
fine-tuning은 pre-train에 비해 많은 계산 비용이 절약되지만, 그래도 모델 매개변수에 대한 추가 학습이랑 고품질의 fine-tuning 용 데이터 수집이 필요하므로 여전히 계산 비용이 존재합니다. 따라서 MedPaLM 같은 일부 연구에서는 모델 매개변수를 학습하지 않고도 PaLM 같은 일반 LLM을 의료 영역에 효율적으로 적용시키기 위한 여러 "prompting" 방법을 통합합니다. 널리 사용되는 프롬프트 방법에는 few-shot, CoT, Self-consistency Tuning 등이 있습니다.
Zero/Few-shot Prompting
Pre-trained 된 언어 모델을 사용하여 특정 작업을 수행할 때, 해당 작업에 대한 별도의 사전 학습이나 특화된 훈련 데이터 없이 직접 작업을 수행하는 방법을 Zero-shot, 소수의 데이터로 새로운 작업을 학습하는 방법을 few-shor prompting이라 합니다. 사용자가 특정 작업을 수행하기 위해 모델에 구체적이고 명확한 프롬프트(모델이 작업의 목적과 방향을 이해하는 데 도움이 되는 지시문)을 제공합니다. 이 방법을 통해 의학적 질문을 이해하고 응답시킬 수 있습니다. 예를 들어 의료 영역에서 MedPaLM은 일반 LLM인 PaLM에 의료 Q&A 쌍과 같은 소수의 다운스트림 예시를 제공하여 성능을 크게 향상시킵니다.
Chain-of-Thought (CoT) Prompting
CoT Prompting은 모델 출력의 정확성과 논리를 크게 향상시킬 수 있는 테크닉입니다. 구체적으로 CoT prompting은 복잡한 다운스트림 문제를 처리할 때 prompting words를 통해 추론의 중간 단계 또는 경로를 생성하도록 모델을 prompting 합니다. 즉, 중간 단계의 추론을 명시적으로 표현하게 하는 방법입니다.
Self-consistency Prompting
모델이 동일한 질문에 여러 번 답을 생성하고, 이들 중 일관되고 신뢰할 수 있는 답변을 선택하는 기법입니다. 따라서 CoT를 기반으로 구축한 경우에 self-consistency promting 을 통해 결과를 개선시킬 수 있습니다. 이 접근 방식은 진단이나 치료에서 일관성이 중요한 의료 영역에서 특히 유용하게 사용됩니다.
Prompt Tuning and Instruction Prompt Tuning
모델에 대한 입력 방식을 조정함으로써 모델이 특정 작업이나 요구 사항에 대해 더 잘 반응하도록 만드는 것에 초점을 맞춥니다. 입력 프롬프트의 조정(Prompt Tuning)은 기존 Pretrained 모델을 사용하고, 입력되는 프롬프트를 조정하여 모델의 반응을 특정 방향으로 유도합니다. Instruction Prompt Tuning은 모델에게 구체적이고 명확한 지시를 포함하는 프롬프트를 제공하여 특정 작업을 수행하도록 합니다. 이런 프롬프트는 모델에게 기대되는 출력 형식까지 제공합니다.
3. Biomedical NLP Tasks
섹션 3에서는 generative / discriminateive task를 소개합니다. 여기에는 임상 적용을 위한 10가지 대표적인 다운 스트림 작업이 포함되어 있습니다. 다운스트림 작업의 종류와 널리 사용되는 평가 데이터셋에 대해 설명하고 적합한 LLM에 대해 논의합니다. 아래 표에 각 다운스트림 작업에 널리 사용되는 평가 데이터 세트 정보가 요약되어 있습니다.

3.1 Discriminative Tasks
Discriminative tasks(판별, 식별 작업)은 주어진 입력 데이터를 기반으로 데이터를 특정 클래스나 범주로 분류/카테고리화 하거나 관련된 정보를 분류,추출해내는 작업입니다. 대표적인 판별 작업으로는 QA, Entity Extraction(개체 추출), Relation Extraction(관계 추출), 텍스트 분류, 자연어추론, Sementic textual similarity(의미론적 텍스트 유사성), 정보 검색 등이 있습니다.
따라서 discriminative task의 일반적인 입력은 의학적 질문, 임상 노트, 의료 문서, 논문 및 환자 EHR 등이 될 수 있습니다. 출력은 입력 텍스트로부터 파생된 구조화되고 분류된 정보일 것이기 때문에 이는 곧 위 task들에 대한 정답이 될 수 있습니다. 그리고 현재 기존 LLM에서도 판별 작업은 많이 연구되고 있으며 이를 통해 입력 텍스트로부터 정보를 추출할 때 많이 사용합니다.
3.2 Generative Tasks
입력 텍스트를 이해하고 분류하는 데 중점을 두는 판별 작업과 달리 생성 task에서는 모델이 주어진 입력을 기반으로 적절한 텍스트를 정확하게 생성하는 것을 목표로 합니다. 대표적인 생성 작업의 예로는 의료 텍스트 요약, 의료 텍스트 생성, 텍스트 단순화 등이 있습니다. 생성 작업에서의 입출력은 일반적으로 길고 상세한 의료 텍스트가 됩니다.
예를 들어 생성형 모델이 환자 기록의 핵심적인 내용을 확실하게 요약해준다면 전문가가 임상 메모를 진단하거나 초안을 작성할 때 도움이 될 수 있습니다. 혹은 환자가 자신의 상태를 관리하기 위한 조언 등을 의료 용어가 섞이지 않은 일반인이 볼수 있도록 쉽게 변경을 해준다거나 하는 단순화하여 정리하는 task에도 적용할 수 있습니다.
3.3 Performance Comparisons
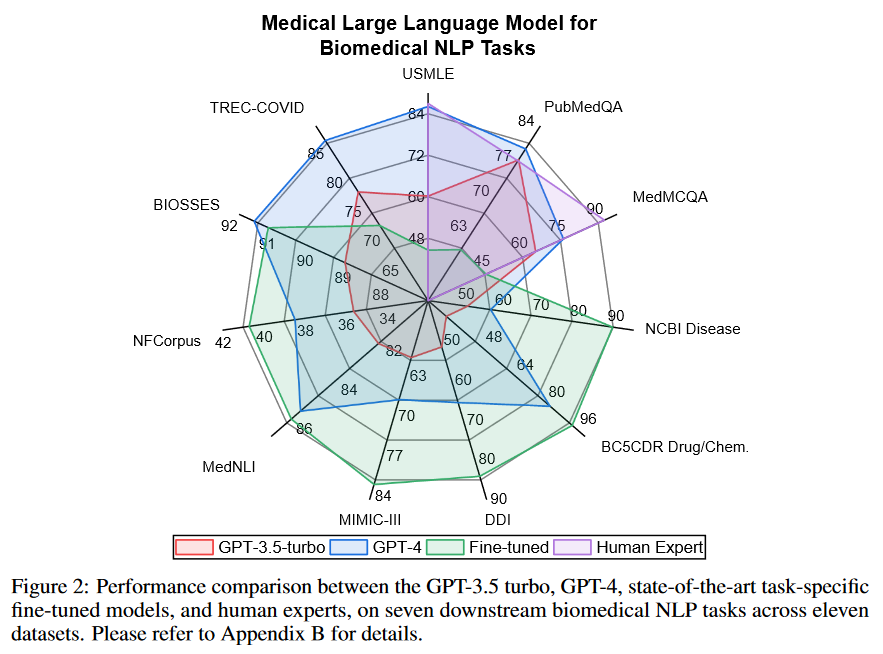
증상을 설명하고 병명을 말하는 것과 같은 QA에서 GPT-4는 거의 전문가와 비슷할 정도의 성능을 보이고 있습니다. 그러나 다른 영역에 대해서는 아직 LLM이 많이 발전해야하는 것이 확인됩니다. 예를 들어 Entity Extraction(개체 추출) 작업(NCBI Disease)에서는 생성모델보다 fine-tuned model이 훨씬 탁월합니다.
LLM이 QA에서 좋은 성능을 보이는 이유는 이것이 Closed ended task이기 때문이라고 저자들은 추측합니다. 즉 정확한 답이 이미 여러 후보 중에 이미 제공되어있다는 것을 말합니다. open-ended는 제공되지 않은 상태에서도 답을 찾아야하는 task를 말합니다.
현재 LLM의 평가는 주로 의료 질문 대답과 같은 특정한 작업에 국한되어 있고, 이러한 평가 방식은 모델의 전반적인 성능을 정확히 반영하지 못할 수 있습니다. 따라서 의료 질문 대답 뿐만 아니라 보다 더 광범위한 평가가 필요합니다.
4. Clinical Applications
LLM의 임상 적용에 대해 논의하는 챕터입니다. LLM의 해결해야하는 Task랑 LLM이 그것을 해결하는 방법, 향후 방향에 대해 다룹니다.
4.1 Medical Diagnosis
의료 진단은 의사가 다양한 검사로부터 얻은 객관적인 의료 데이터와 증상들을 종합하여 환자에게 발생할 가능성이 가장 높은 건강 문제를 결론짓는 것과 관련됩니다. 대부분의 질병에 대한 치료효과는 시간에 매우 민감하기 때문에 환자를 정확하고 시기적절하게 진단하는 것이 항상 중요합니다. 어떤 질병이든 진단을 좋치거나 잘못된 진단을 하게 되면 사소한 불편함부터 사망까지 심각도에 따라 부정적인 결과를 초래하는 경우가 많습니다. 예를 들어 유방암은 적절한 검사를 수행할 수 있는 전문인력이 부족하기 때문에 세계에서 사망률이 가장 높습니다. 따라서 LLM을 의료 진단 파이프라인에 통합하면 전문 의료 서비스의 접근성이 높아질 것입니다.
예를 들어 최근 의료 진단에 LLM을 사용하는 방법은 질병의 병리와 관련된 상위 경로를 반환하는 그래프 모델을 이용하는 것입니다. 병명을 진단하는 LLM이 있을 때, 왜 그런 병을 진단했는지에 대한 설명이 없다면 사람은 그 결론을 이해하기 어렵습니다. 따라서 그 과정을 어느정도 설명 가능한 경로(paths)를 아는 것이 중요합니다. 인코더가 path representations 를 생성하고 path ranker가 경로를 평가해 입력과의 논리적 연관성을 판단하여 가능한 질병 진단의 순위 목록을 생성합니다. 기존 모델 위에 이 방법을 사용할 경우 상태에 따라 8~18% 정도 성능이 향상되는 것으로 입증되었습니다.(CUI-F score 기준)
추가 논의점) 의료 진단을 의사가 없이 혼자 맡길 정도로 사용하는 것의 한 가지 뚜렷한 한계점은 바로 환자의 주관적인 입력에 전적으로 의존한다는 것입니다. LLM은 주로 텍스트 기반이므로 의료 진단 이미지를 분석하는 기본 능력이 부족합니다. 그리고 객관적인 의료 진단은 시각적 이미지에 의존하는 경우가 많기 때문에 LLM은 질병 진단을 뒷받침할 구체적이고 시각적인 증거가 부족하여 진단 평가를 직접 수행할 수 없는 경우가 많습니다. 그러나 다른 비전 기반의 모델의 정확성을 향상시키는데 도움이 되는 논리적 추론 도구로서 진단에 도움이 될 수 있습니다. 대표적으로 ChatCAD가 이 논리를 활용해 진단을 생성합니다.
이미지는 먼저 기존의 CAD(Computer-aided diagnosis, 컴퓨터 지원 진단) 모델에 입력되어 텐서 출력을 얻습니다. 이 출력이 자연어로 번역된 후 ChatCAD에 입력되어 결과를 요약하고 진단을 공식화합니다. ChatCAD는 성능이 좋다는 말이 어렷 언급되고, 최근의 GPT-4V(비전) 모델은 일반 영역의 이미지 해석은 되지만 아직 의료 영상에 대해서는 해석을 못합니다. 그럼에도 불구하고 위에 언급했던 LLM 구현 방법은 모두 사전에 이미지를 텍스트로 변환하는 것에 의존하는 등의 한계점이 여전히 존재합니다. 그리고 LLM의 전통적 문제인 개인 정보 보호, Bias 가능성 등도 여전히 존재합니다.
4.2 Formatting and ICD-Coding
4.3 Clinical Report Generation
4.4 Medical Education
4.5 Medical Robotics
4.6 Medical Language Translation
4.7 Mental Health Support
5. Challenges
5.1 Hallucination
5.2 Lack of Evaluation Benchmarks and Metrics
5.3 Domain Data Limitations
5.4 New Knowledge Adaptation
5.5 Behavior Alignment
5.6 Ethical, Legal and Safety Concerns
6. Future Directions
6.1 Introduction of New Benchmarks
6.2 Interdisciplinary Collaborations
6.3 Multimodal LLM Integrated with Time-Series, Visual, and Audio Data
6.4 Medical Agents
7. Conclusion
Reference:
A Survey of Large Language Models in Medicine: Principles, Applications, and Challenges
Large language models (LLMs), such as ChatGPT, have received substantial attention due to their impressive human language understanding and generation capabilities. Therefore, the application of LLMs in medicine to assist physicians and patient care emerge
arxiv.org
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
Although pretrained language models can be fine-tuned to produce state-of-the-art results for a very wide range of language understanding tasks, the dynamics of this process are not well understood, especially in the low data regime. Why can we use relativ
arxiv.org
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org