구글 리서치에서 발표한 ToTTo 데이터셋에 대한 논문입니다. Table-to-Text generation 을 위한 데이터셋인데, 기존의 데이터셋을 이용한 텍스트 요약, Data-to-text dataset 등에서는 할루시네이션을 잘 일으킨다는 문제가 있었습니다. 이 때 할루시네이션은 맥락 상 말도 안되는 내용을 쓴다기 보다는 원문(source)에 충실하지 않은 텍스트 생성을 전반적으로 의미합니다. 이 할루시네이션 때문에 의료와 같이 높은 정확도가 요구되는 응용 분야에서는 사용 못하게 될 수도 있죠.

Wikibio 데이터셋에 대한 베이스라인 신경망 모델의 예측 결과입니다. 벨기에 축구 스타디움에 대한 infobox 항목을 요약하는데, 피겨스케이트 선수라고 잘못 요약한 것을 확인할 수 있습니다. 이 같은 현상을 hallucination 이라 합니다.
이런 말을 한다는 건 ToTTo 데이터셋은 할루시네이션이 잘 안 일어나는 데이터셋이거나, 혹은 일어나더라도 이를 잘 감지할 수 있는 데이터셋이라는 말을 하겠죠? 어떤 방식으로 구성되어 있는지는 하단의 논문 내용에서 확인해보겠습니다.
ToTTo: A Controlled Table-To-Text Generation Dataset
Abstract
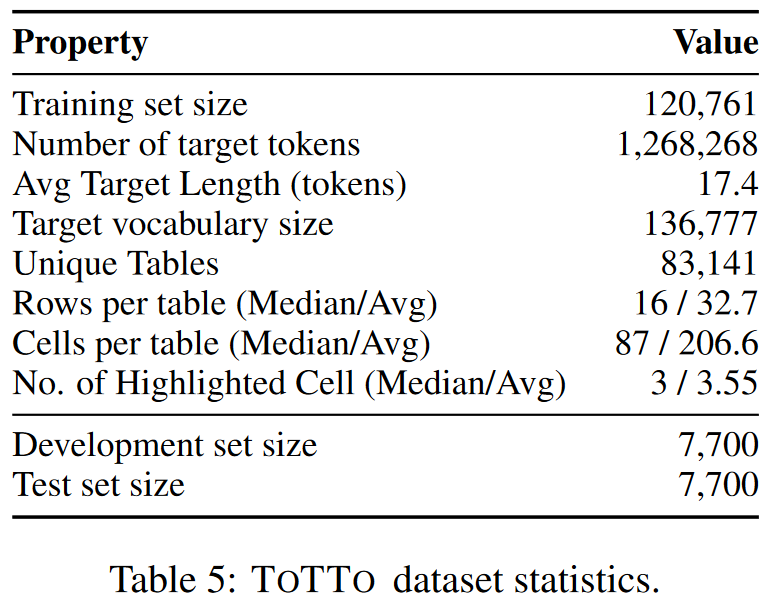
본 논문에서는 12만개가 넘는 훈련 예제가 있는 ToTTo라는 open-domain English Table-to-text dataset 을 제공합니다. Wikipedia table 과 하이라이트된 테이블 셀 세트가 주어지면, 한 문장으로 된 설명을 생성합니다. target(설명)을 생성할 때, 자연스러우면서도 source 테이블에 충실한 출력을 얻기 위해 주석자가 위키피디아에서 기존 후보 문장을 직접 수정하는 데이터 세트 구성 프로세스를 거쳤습니다.
데이터세트와 주석 프로세스에 대한 체계적인 분석과 SOTA 베이스라인을 통해 달성한 결과를 제시합니다.
1 Introduction
Data-to-text generation 은 테이블 같은 구조화된 데이터 형식의 source $x$를 조건으로 하는 target textual description $y$를 생성하는 작업입니다. 기존의 데이터를 텍스트로 변환하는 작업은 neural generation model 을 주로 사용하는데, neural model은 hallucination에 취약한 것으로 알려져 있습니다. hallucination이란 겉보기에는 유창해보이지만, source에 기반하지 않은 text를 생성하는 것을 뜻합니다. 그리고 선행 연구를 통해 source content가 원문이 아닌 표 형식으로 구조화되어 있으면 생성된 text에 대해 source text에 기반하여 생성했는지에 대한 충실도(faithfulness)를 평가하는 것이 더 쉽다는 것이 알려져 있습니다. 또한 구조화된 데이터는 모델에 대해 추론과 표현에 대한 수치적인 테스트가 가능하며 NLU(자연어 이해)에 있어 보완적인 기능을 제공할 수 있습니다.
그러나 데이터를 텍스트로 변환하는 data-to-text dataset을 구성하는 것은 디자인 설계와 주석 프로세스라는 2개의 축에서 어려울 수 있습니다. 첫째로, 요약(summarization) 같은 open-ended 출력을 가지는 작업은 생성할 항목에 대한 모델의 명시적인 신호가 부족하여 주관적인 내용 및 평가 문제로 이어질 수 있습니다. 반면, 완전히 지정된 의미 표현을 생성하는 것으로 제한되는 data-text task는 추론을 수행하는 모델의 능력을 평가하지 않기 때문에, 작업에서 상당한 양의 문제를 고려하지 않습니다.
둘째로, 자연스러우면서도 깨끗한 target text를 얻기 위해 주석 프로세스를 설계하는 것도 중요한 과제 중 하나입니다. 많은 데이터세트에서 사용하는 전략 중 하나는 주석자가 처음부터 target을 작성하도록 하는 것입니다. 이런 방법의 문제점은 구조나 스타일 측면에서 다양성이 부족한 경우가 많을 수 있습니다. 이의 대안은 자연적으로 발생하는 text를 표와 연결하는 것입니다. 더 다양하고 자연적으로 발생하는 target은 noise가 많고, source에서 추론할 수 없는 정보를 포함하는 경우가 많습니다. 이것은 모델링의 약점과, 데이터의 노이즈를 구분할 수 없게 만드는 문제를 만들 수 있습니다.
본 논문은 open-domain table-to-text generation dataset인 ToTTo를 제공하며, 위의 과제를 해결하기 위해 새로운 작업 설계 및 주석 프로세스를 사용합니다. 첫째로, ToTTo는 controlled generation task, 제어되는 생성 작업을 제안합니다. Wikipedia 테이블과 강조 표시된 셀 집합이 source $x$로 주어지면 목표는 단일 문장 설명 $y$를 생성하는 것입니다. 강조된 셀은 구체적인 의미 표현을 명시하지 않고, target 문장이 설명해야할 큰 표의 일부를 식별하는 용도로 사용됩니다.
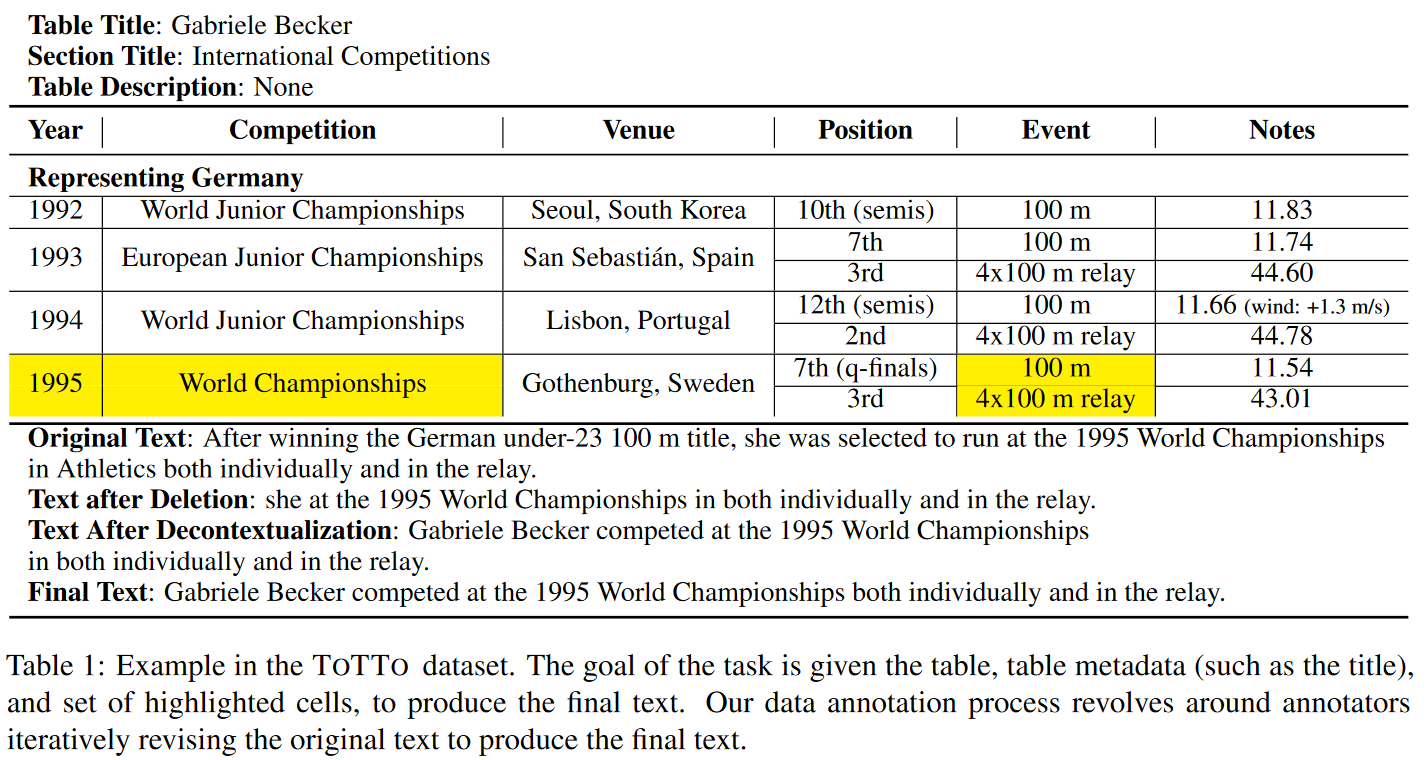
ToTTo dataset의 예시로, 테이블과 테이블 메타데이터, 그리고 하이라이트된 셀과 생성해야하는 gold target text까지 제공됩니다. 기존의 데이터셋처럼 어떤 모델을 거쳐 나온 출력 뿐 아니라 주석자들이 직접 검수하고 수정한 Text를 제공합니다.
이 후 데이터 세트 구성 방법에 대해 설명이 나오는데, 이 부분은 생략하겠습니다. (하단 원문 논문 링크 참조)
2 Related Work
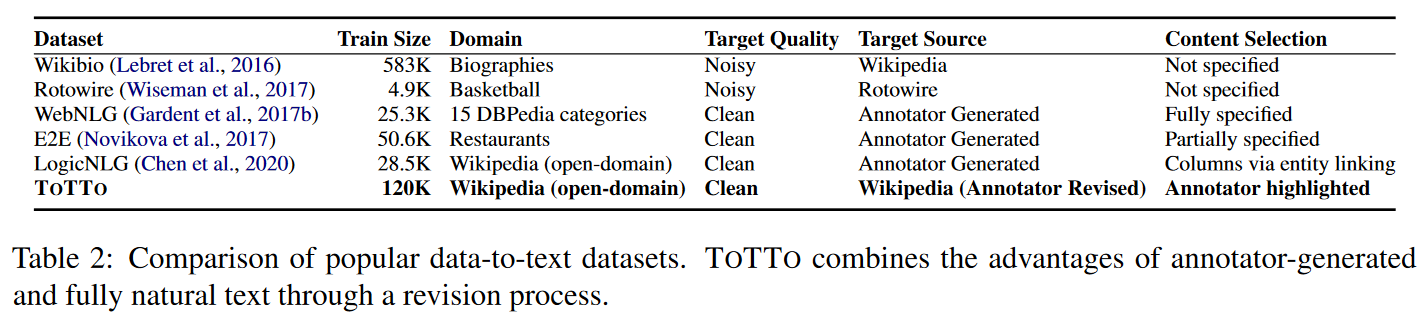
기존 Data-to-text dataset 들에 대한 요약입니다. Neural 접근법 이전의 생성 시스템은 전형적으로 content selection(말할 내용) 단계와 surface realization(말할 방법)으로 분리되었습니다. 따라서 많은 dataset들은 후자 단계에 초점을 맞췄습니다. Neural 접근법은 이미 유창한 text를 생성하는 데 매우 강력하기 때문에 전반적인 작업 복잡도가 줄어들게 됩니다.
따라서 일부 최신의 데이터세트들은 content selection을 요약 문제로 구성하여 작업에 통합하는 것을 제안했습니다. 그러나 요약은 훨씬 더 주관적이기 때문에 작업에 대한 제약이 부족하고 평가가 어려울 수 있습니다.
어노테이션 프로세스 중에는 위에서 말했듯 1) 처음부터 source를 보고 target을 직접 쓰는 방법 2) 웹 등에서 존재하는 알맞은 문장을 가져다 쓰는 방법 등이 있었는데 1번의 경우는 다양성이 부족할 수 있다는 문제, 2번 같은 경우는 노이즈가 너무 많다는 문제가 있기 때문에 ToTTo는 주석자들이 Wikipedia의 후보 문장을 source에 좀 더 알맞도록 수정하는 새로운 어노테이션 방식을 택했기 때문에 다양성도 더 높고, 노이즈도 더 적다는 장점이 있습니다.
3 Preliminaries
단순화를 위해 테이블 $t$를 셀 집합 $t=\{c_j\}^{\tau}_{j=1}$로 정의합니다. $\tau$는 테이블의 셀 수 입니다.
각 셀에는 다음이 포함됩니다.
- 문자열 값
- 행 또는 열 header인지 아닌지의 여부
- 테이블에서 셀의 행, 열 위치
- 행과 열의 범위
메타 데이터를 다음과 같이 $\mathbf{m}=(m_{page-title}, m_{second-title}, m_{section-text})$로 정의합니다. 각각 페이지 제목, 섹션 제목, 제목 및 섹션 텍스트(있는 경우)의 처음 2개 문장까지를 나타냅니다. 이는 테이블 내용에 대한 context를 제공하는 데 도움이 될 수 있습니다.
Text 를 $\mathbf{s}=(s_1, ..., s_{\eta})$로 정의하면 어노테이션 예제를 위의 요소들과 함께 $d=(t,m,s)$로 테이블, 테이블 메타데이터, 문장의 튜플로 정의합니다. $\mathbf{D}= \{d_n\}^{N}_{n=1}$은 $N$개의 어노테이션 예제 데이터셋을 의미합니다.
5 Data Annotation Process

기존 위키디피아 문장을 단계별로 수정하는 새로운 데이터 주석 전략을 사용. 위키디피아에서 표 데이터를 모으고, 페이지 텍스트와 표 사이의 단어 오버랩이나 도표 데이터를 참조하는 하이퍼링크와 같은 휴리스틱에 따라 지원된 페이지 컨텍스트로부터 문장이 요약됨(Original). 이 때 표는 요약된 문장과 짝을 이룬다. 요약된 문장은 표에서 지원되지 않는 정보를 포함할 수 있고 문장자체가 아닌 표에만 있는 선행조건을 가진 대명사를 포함할 수 있다.
그 다음 어노테이터가 표에서 문장을 지원하는 셀을 강조 표시하고 지원하지 않는 문장의 구문을 삭제(deletion)
필요한 경우 문장이 독립적이고 문법적으로 정확하도록 문장을 문맥에서 떼어놓고 해석(Decontectulization & Grammer)
6 Dataset Analysis
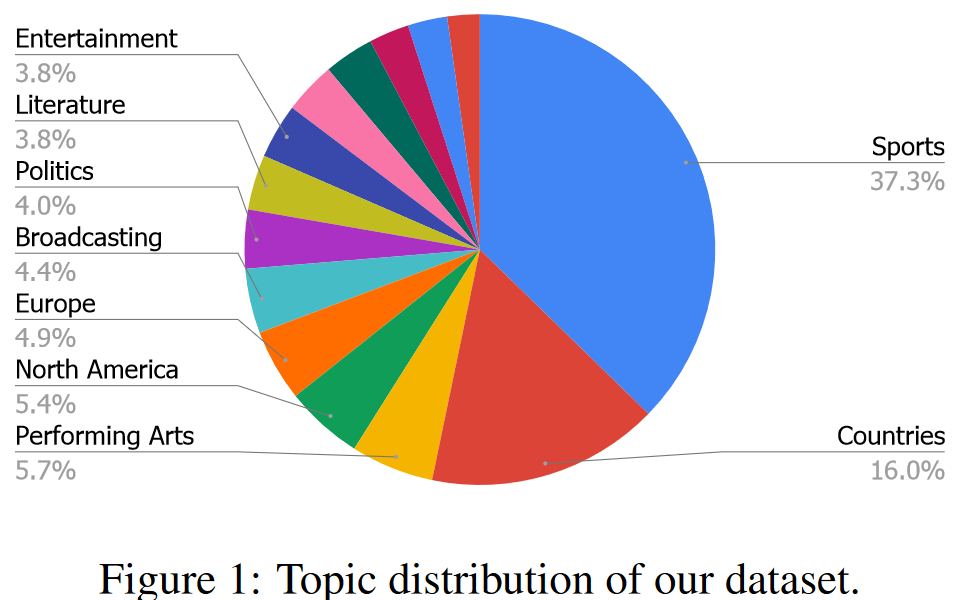
- 44개 카테고리에 걸쳐 ToTTo 데이터셋에 대한 주제 분석을 수행함. 그 결과 스포츠와 국가 항목은 전체 데이터셋의 56.4%를 구성. 더 자세히 보면 스포츠에선 축구/올림픽, 국가에선 인구/건물 등 세분화된 다양한 항목으로 구성됨. 나머지 44%는 공연예술, 운송, 엔터테인먼트 등 훨씬 더 광범위한 주제들로 구성됨
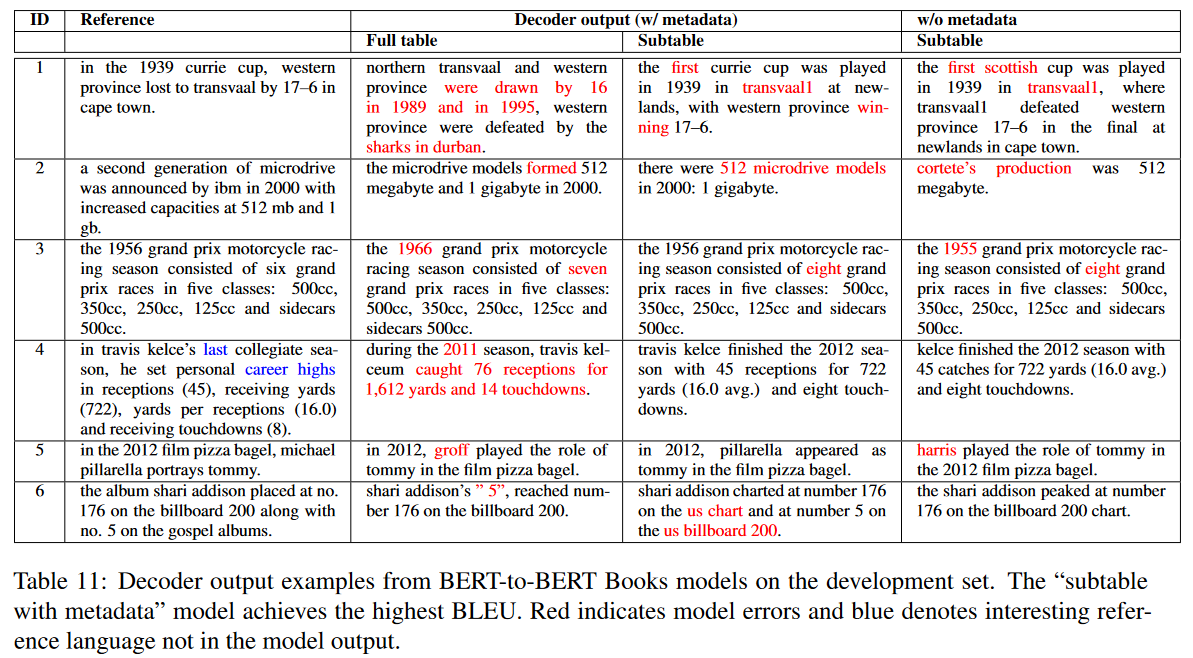
- 또한 데이터셋에서 무작위로 선택된 100개의 예시를 가지고 다양한 종류의 언어 현상에 대한 수동 분석(manual analysis)을 실시함. 아래 표는 페이지와 섹션 제목에 대한 참조를 필요로하는 예제 부분과 현재 시스템에 잠재적으로 새로운 문제를 야기할 수 있는 데이터셋의 언어현상을 요약함
Reference:
https://arxiv.org/abs/2004.14373
ToTTo: A Controlled Table-To-Text Generation Dataset
We present ToTTo, an open-domain English table-to-text dataset with over 120,000 training examples that proposes a controlled generation task: given a Wikipedia table and a set of highlighted table cells, produce a one-sentence description. To obtain gener
arxiv.org
https://blog.research.google/2021/01/totto-controlled-table-to-text.html
ToTTo: A Controlled Table-to-Text Generation Dataset
Posted by Ankur Parikh and Xuezhi Wang, Research Scientists, Google Research In the last few years, research in natural language generation, used for tasks like text summarization, has made tremendous progress. Yet, despite achieving high levels of fluency
blog.research.google