이번 포스팅에서는 Generative / Discriminative model이 무엇이고, 이 둘의 차이점에 대해 다룹니다.
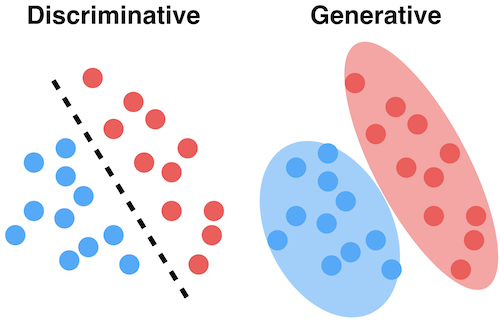
머신러닝 모델은 크게 2가지 타입, Generative model과 Discriminative model로 분류될 수 있습니다. 우리는 이미 이런 모델들을 사용해 이미지를 생성하기도 하고, 자연어를 처리하기도 하고, 객체 탐지나 세그멘테이션 등 꽤 어려운 task들을 수행해내고 있습니다.
그러나 근본적으로, 이 2개의 용어는 통계적인 분류 문제에 대한 모델을 설명하는 것에서 정의됩니다.
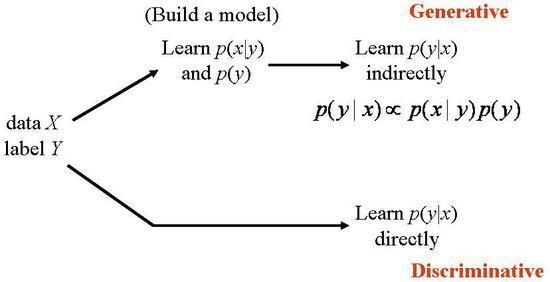
Classification 의 정의를, 위 그림에 맞게 다시 설명해봅시다. 각 데이터 $X$가 있고, 레이블된 클래스 값 $Y$가 존재합니다. Classification는 입력 데이터를 사전에 정의된 여러 클래스나 범주에 할당하는 작업으로, 수학적으로 Classification의 목적은 $P(Y|X)$를 최대화 하는 $Y$를 찾는 것 입니다. 즉 새로운 $X$에 대해 그 $X$가 어느 클래스 $Y$로 분류될 가능성이 최대화된 $Y$를 찾는 작업입니다.
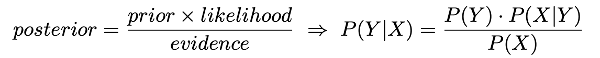
이를 어떻게 학습할지 모델을 정하는 방법론이 Generative model과 Discriminative model 입니다.
간단히 이 둘의 특징에 대해 요약하자면 다음과 같습니다.
- Generative model : 주어진 입력 데이터로부터 주어진 데이터 분포를 학습하고, 그 분포를 기반으로 새로운 데이터를 생성/분류, class의 분포에 집중, Joint probability $p(x,y)$
- Discriminative model : 입력 데이터를 클래스 or 라벨에 직접 연결시키는 모델로, 주어진 입력 데이터가 어떤 클래스에 속하는지를 분류하는 것이 목표, class의 차이점에 집중, Conditional Probability $p(y|x)$
Discriminative model
입력값과 출력값을 직접 연결시켜 decision boundary를 찾는 것을 목표로 하는 방식을 Discriminative(판별/변별) 알고리즘이라 합니다. 그런데 decision boundary가 갑자기 어떻가 나오는가? 이해가 안 갈 수 있기 때문에 분류 알고리즘을 풀어 설명해봅시다.
- Classification : 어떤 입력값(input) $x$가 주어졌을 때 그 결과값(label)이 $y$일 확률을 알아내는 것
- => Find $p(y|x)$
- => 새로운 데이터가 들어오면 $x$라는 데이터를 기반으로, $y$의 클래스를 확률적으로 예측
- => 이 때 확률적으로 어떻게 예측하는가? 구분선(Decision boundary)을 기준으로 이를 분류하고 확률값을 연산한다.
Discriminative 방식의 머신러닝은 다음 과정으로 이루어집니다.
1. 특정 입력값 $X$에 대해 조건부 확률 분포(Conditional Probability Distribution)을 만들어낸다.
=> 이 때 조건부 확률 분포는 입력값 $X$가 특정 값이라는 조건으로 주어질 때의 $Y$값의 분포도를 기술하는 데이터 형식
2. 조건부 확률 분포에 근거한 input $X$와 label(output) $Y$로 부터 벡터를 만들어낸다.
3. $X$값들의 성질(결과값, = $Y$값)을 잘 구분할 수 있는 선(decision boundary) 를 만들어낸다.
4. 만들어진 선을 기반으로 새로운 데이터($X'$)가 입력 되었을 때 선으로부터 음 혹은 양의 방향으로 거리를 재어 확률을 구한다.

대표적인 방식이 Logistic regression, SVM, Linear regression, Neural network 등이 있습니다. 장/단점이 있는데 이는 마지막에 Generative model과 비교하면서 다루도록 하겠습니다.
Generative model
Discriminative 방식과는 다른 분류 알고리즘, 구분하는 것을 넘어서서 분류 카테고리에 맞는 데이터를 생성하는 방식입니다. 이 방식은 생성되는 입력과 결과 데이터는 분류 클래스별로 특정한 통계적 분포를 따른다고 가정하는 방식입니다.
입력값 $x$와 결과값 $y$가 주어질 때, 이들은 일정한 분포 규칙 속에 존재합니다. 그 분포 규칙은 분류 클래스 마다 다르고, Normal Distribution 등의 통계적인 방법론을 따릅니다.
분포규칙은 수학적으로 결합 확률 분포(Joint Probability Distribution) $p(x,y)$로 표현합니다. 결합확률분포 $p(x,y)$를 나타내기 위해서 필요한 것은 Conditional density $p(y)$랑, 각 클래스의 prior distribution 인 $p(x|y)$가 필요합니다.
그러나 우리가 분류에 필요한 것은 사후 확률 $p(y|x)$입니다. $p(x,y)$를 모델링하는 것과 $p(y|x)$를 구하는 것과 무슨 연관성이 있는가? 하면 이는 베이즈 정리로 유도가 가능합니다. 이에 대해서는 참고할 만한 사이트를 공유합니다.
Joint Probability: Definition, Formula, and Example
Joint probability is a statistical measure that calculates the likelihood of two events occurring together and at the same point in time.
www.investopedia.com
다시 정리를 해보면 결합확률 분포 $p(x,y)$를 모델링하고, 간접적으로 베이즈 정리를 통해 결합확률 분포를 조건부 확률 $p(y|x)$로 나타낼 수 있습니다. 이렇게 입력값과 출력값 사이에 분포규칙의 개념을 적용한 방식을 Generative 알고리즘이라 합니다.
Geneartive 방식의 머신러닝은 다음 과정으로 이루어집니다.
1. 주어진 데이터와 결과값을 이용해 모든 $x$와 모든 $y$에 대해 conditional density $p(y)$랑 각 클래스의 prior distribution $p(x|y)$를 이용해 Joint Probability Distribution $p(x,y)$를 생성합니다.
2. 결합확률 분포로부터 어떤 확률 분포모델이 데이터 분포모델에 적합한지를 측정(estimation)합니다. (difficult)
3. 측정해낸 확률 분포모델을 기반으로 사후확률을 알아낼 수 있다. $p(y|x) ∝ p(x,y)$
4. 즉, $x$가 주어질 경우, $y$의 확률을 예측하려면 $x,y$에 대한 결합확률분포공식(모델)과 $x$의 확률(경계확률)을 알면 구할 수 있다.
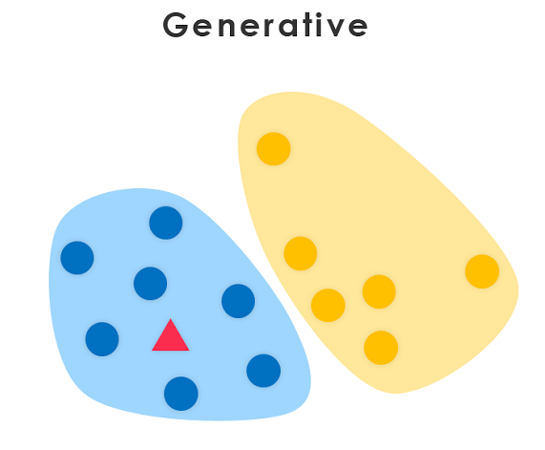
대표적인 방식으로는 Naive bayes, Markov Model, GAN 등이 있습니다.
Generative model vs Discriminative model
다시 이 둘을 요약하자면, Discriminative model은 데이터 공간에 경계를 그리는 반면, Generative model은 데이터가 공간 전체에 배치되는 방식을 모델링합니다. Generative model은 데이터가 어떻게 생성되었는지를 설명할 수 있는 반면, Discriminative model은 데이터의 레이블을 예측하는 것에 중점을 둡니다.
직접적으로 $p(y|x)$를 학습 시켜 그 학습된 파라미터를 이용해 직접 output $y$를 계산하는 모델이 Discriminative model, Joint probability $p(x,y)$를 통해 간접적으로 $p(y|x)$를 구해 새로운 데이터에 대해 어떤 class에 들어가야 하는지 결정을 내려 $y$를 계산하는 것이 Generative model이 됩니다.
Discriminative model의 장점은, 데이터가 충분할 경우 좋은 성능을 보여준다는 점입니다. 그러나 데이터를 구분하는데 목푤 두기 때문에, 데이터가 실제 어떤 모습인지 본질을 이해하기는 어렵습니다.
Generative model의 장점은, 상대적으로 적은 데이터에 대해서도 준수한 성능을 보인다는 점입니다. 그리고 데이터 자체의 특성을 파악하기가 좋고, 데이터를 생성해내어 새로운 결과물을 만들수도 있습니다. 그러나 단점은, 데이터가 많은 경우 Discriminative model에 비해 성능이 떨어질 수 있고 unseen, 즉 한번도 보지 못한 데이터에 대한 처리가 Discriminative에 비해 부족합니다. 또한 데이터에 이상치가 많은 경우, Discrminative model에 비해 더 큰 성능 저하가 나타납니다.
이러한 두 개의 차이를 잘 알고 사용하는 것이 중요하며, 꼭 하나만 사용하는 것이 아닌 혼합되어 사용하기도 합니다. 여기까지 Generative model과 Discriminative model에 대해 알아보았습니다. 감사합니다.

'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 선형 회귀 ( Linear Regression ) (0) | 2023.09.02 |
|---|---|
| [DL] 역전파를 이용한 2층 신경망 학습 구현 (0) | 2023.08.22 |
| [DL] 역전파 ( Backward-propagation ) (0) | 2023.08.21 |
| [DL] 학습 알고리즘 구현 ( 2층 신경망 ) (0) | 2023.08.18 |
| [DL] 경사 하강법 ( Gradient Descent ) (0) | 2023.08.17 |