기계학습 문제는 학습의 목표가 최적의 매개변수를 찾는 것이고, 이는 곧 손실 함수가 최솟값이 될 때의 매개변수를 찾는 것과 동일합니다. 이 때 기울기를 사용해서 함수의 최솟값을 찾는 아이디어가 경사 하강법(Gradient Descent) 입니다.
[DL] 손실 함수 ( Loss function )
신경망 학습이란 train 데이터로부터 가중치 매개변수의 최적값을 자동으로 얻는 것을 뜻합니다. 이번 포스팅에서는 신경망이 학습할 수 있도록 해주는 지표인 손실 함수에 대해 알아보도록 하
songsite123.tistory.com
지난 포스팅에서 손실 함수의 개념을 알아보았습니다. 손실함수는 신경망의 성능의 '나쁨'을 나타내는 지표로 현재의 신경망이 훈련 데이터를 얼마나 잘 처리하지 못하는가 를 나타냅니다.
이제 손실함수의 기울기를 구해서 손실함수의 최솟값을 나타내는 최적의 매개변수를 찾아야 합니다. 기울기를 구하기 위해서는 미분을 사용합니다. 근데 어떤 값에 대해서 미분을 해야할까요?
손실함수는 "함수" 입니다. 즉 입력과 출력이 정해져있고, 계수와 변수가 존재합니다.
손실함수의 변수는 가중치($W$)와 편향($b$)가 되고, 입력 데이터는 손실함수의 계수가 됩니다. 자칫 생각하면 잘못 생각하기가 쉬운 내용입니다. 신경망의 입력으로 훈련 데이터를 넣으니까 변수가 입력 데이터가 되어야 하는 거 아닌가? 라고 생각하기 쉽죠.
그러나 학습의 과정에서 어떤 것이 변화하고, 어떤 것이 변하지 않는지를 생각해보면 왜 가중치와 바이어스가 변수인지 알 수 있습니다. 학습 과정은 어떤 입력에 대해 출력(예측값)을 구하고, 실제 정답과의 차이를 손실함수를 통해 구한 다음 아직 정확히 배우진 않았지만 역전파 과정을 통해 가중치와 바이어스 값을 갱신 하는 과정입니다. 이 때 어느 정도 값을 갱신하는지는 손실함수에 의해 계산되게 될것이고, 그것이 오늘 배우는 경사 하강법입니다. 이 과정 중에서 훈련 데이터가 변하나요? 당연히 한 개의 훈련 데이터에 대한 학습이 끝나면 그 다음 다양한 훈련 데이터들에 대해 연산을 진행하겠지만 예측값을 구하고, 오차를 구하고, 그 오차로 인해 업데이트 하는 값은 데이터가 아닌 가중치와 바이어스 입니다. 따라서 학습 중 손실함수는 변수가 가중치와 편향, 계수가 입력(훈련)데이터인 함수로 생각할 수 있습니다.
경사 하강법(Gradient Descent) 이란?

위에서 말했듯 손실함수는 가중치와 바이어스의 함수입니다. Cost 함수가 손실함수를 의미합니다. 경사 하강법에서는 최소인 지점을 찾기 위해 접선의 기울기와 반대 방향으로 이동하는 방법을 통해 최솟값을 탐색합니다. 현재 빨간 접선이 그어진 지점의 기울기는 양수(+) 이므로, 그 반대 방향인 음수(-)방향으로 이동하여 최솟값에 가까운 지점으로 접근합니다.
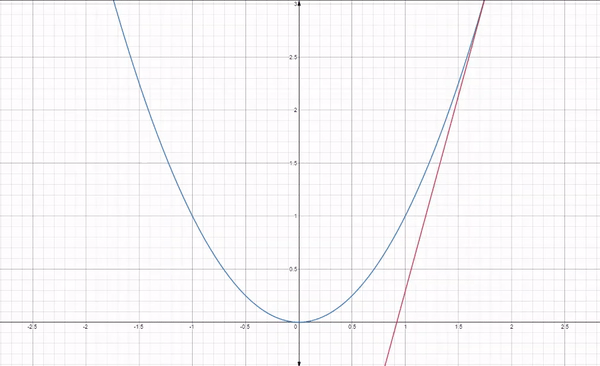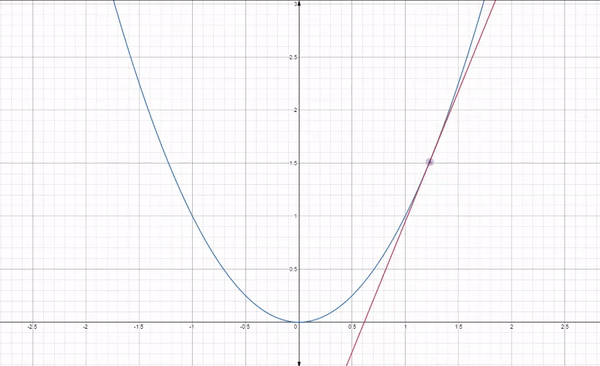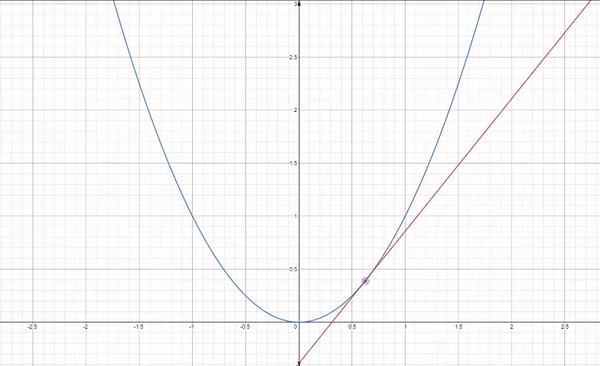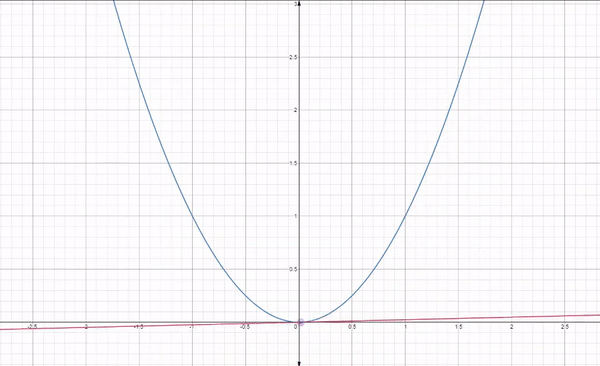
이런 식으로 각 지점에 대해서 기울기값의 반대로 이동하면서 최소 지점을 탐색하게 됩니다. 위에는 이어지는 매끄러운 과정처럼 보이지만 실제 과정은 아래의 반복입니다.
- 현 위치에서 기울기를 구하고, 그 반대 방향으로 일정 거리만큼 이동
- 이동한 지점에서 기울기를 구함
- 1,2 번을 계속 반복한다.
이는 아래와 같은 수식이 반복적으로 수행된다는 것으로 나타낼 수 있습니다.
$$ W := W - \alpha \dfrac{\partial f}{\partial W} $$
책에는 조금 다른 형태로 나타나 있지만, 맨 처음 그림처럼 손실함수를 $W$와 $b$의 함수로 정의하면, $W$ 값을 새로 갱신하는 식으로 표현할 수 있습니다. 이 때 원래의 $W$에서 손실함수 $f$를 $W$에 대해 편미분 한 값, 즉 기울기에 $\alpha$라는 계수를 붙인 값을 뺌으로써 기울기의 반대방향으로 이동하는 것을 의미합니다.
이 때 $\alpha$는 갱신하는 양, 갱신하는 비율을 나타냅니다. 이를 학습률, learning rate 라고 합니다.
또한 위 식은 각 변수에 대한 편미분으로 정의되므로, 다음처럼 표기하기도 합니다.
$$ W := W - \alpha \nabla f(W) $$
학습률은 값은 초반에 특정해놓고 사용해야 합니다. 학습 중에도 변경시킬수 있는 값이며 보통 신경망 학습에서 학습률을 변경해가며 올바르게 학습하고 있는지 확인하는 하이퍼 파라미터 중 하나입니다. 학습률은 매우 중요한 값으로, 학습률에 따라 학습이 제대로 될지 안될지가 결정될 수 있습니다.
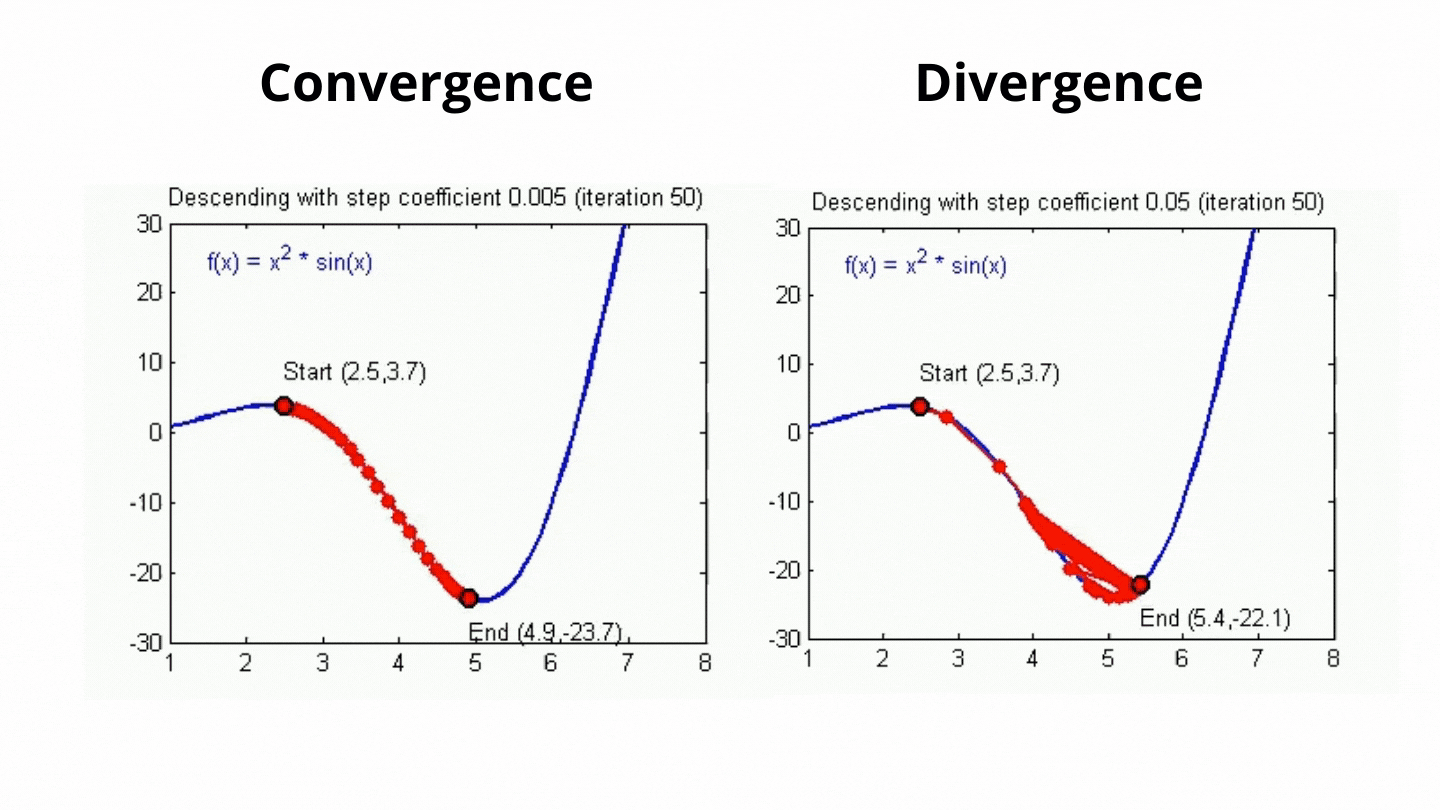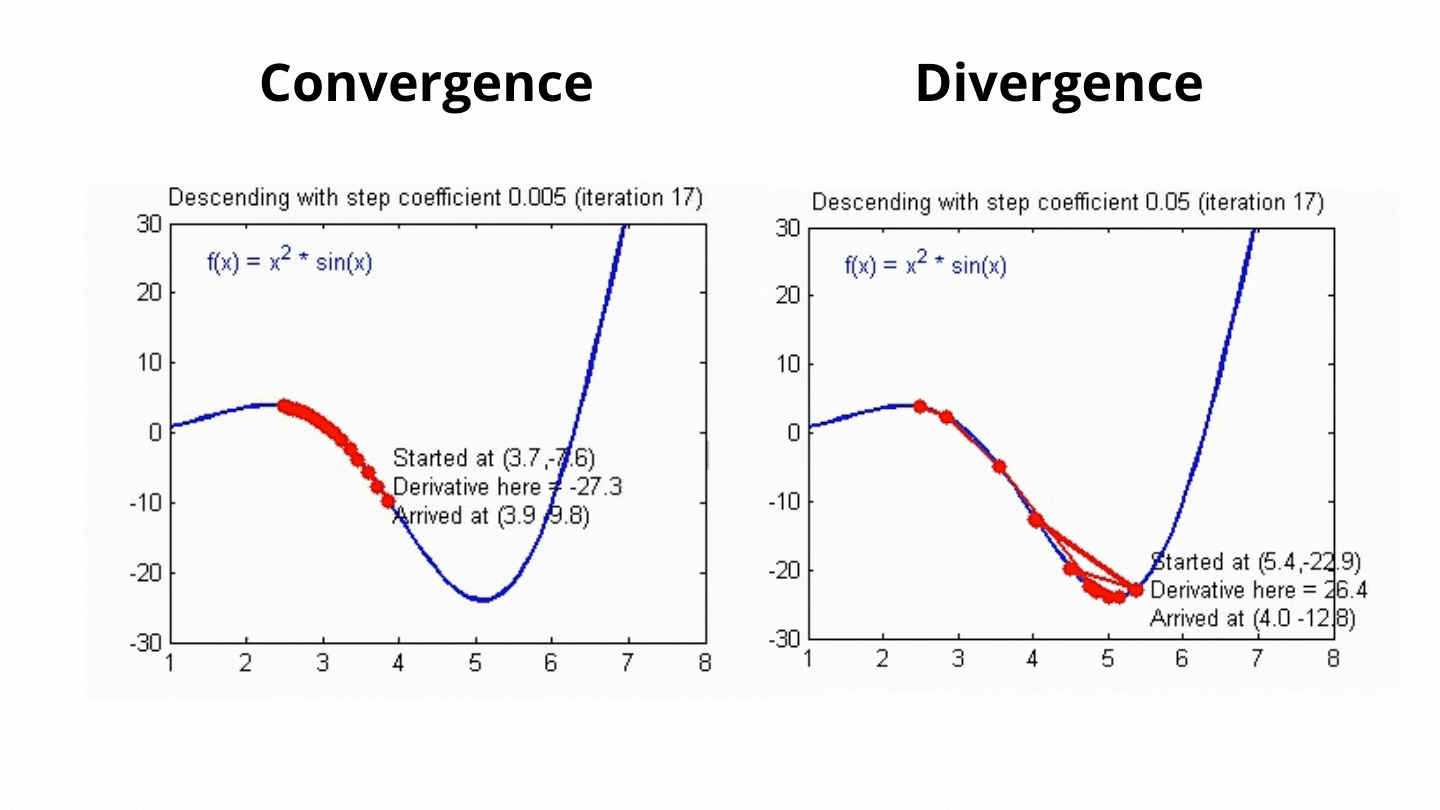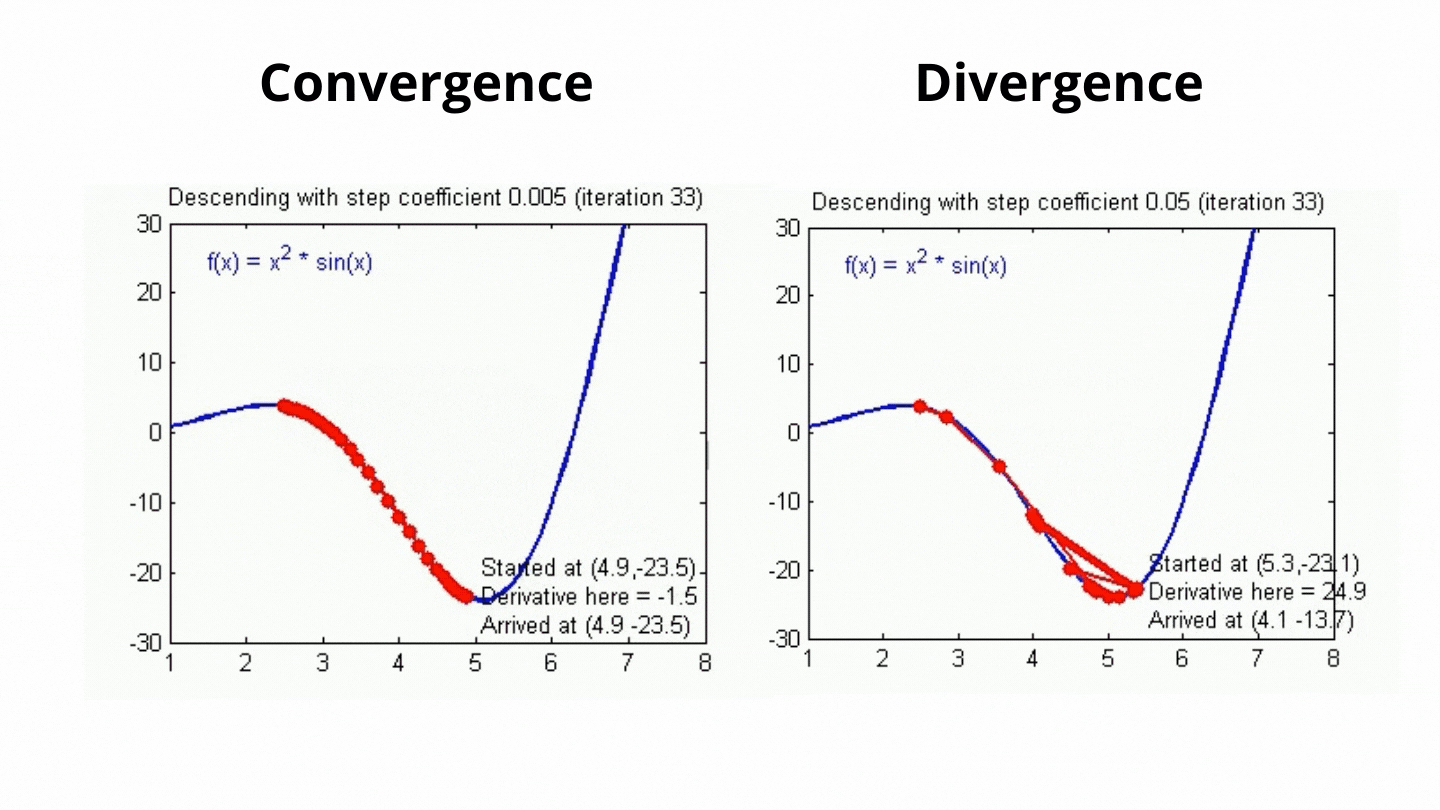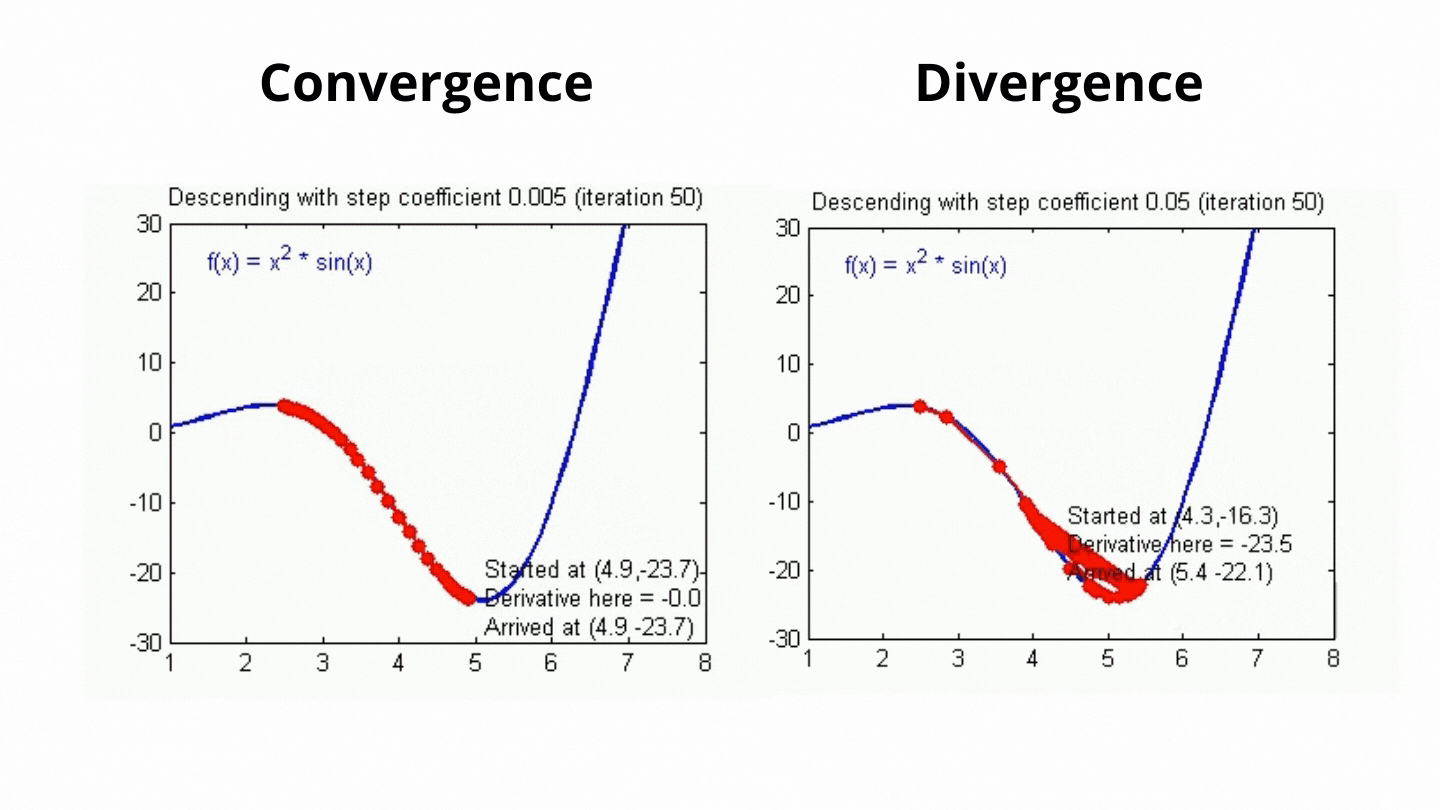
왼쪽은 오른쪽에 비해 점이 많이 찍히는 것을 확인할 수 있고 오른쪽은 점이 왼쪽에 비해 먼 간격으로 찍히는 것을 확인할 수 있습니다. 왼쪽 그래프는 최솟값으로 잘 수렴하는 반면 오른쪽 그래프는 특정 값으로 수렴되지 않고 발산하는 것을 확인할 수 있습니다. 이는 학습률이 너무 큰 나머지 최솟값 인근의 값에서 최솟값으로 가지 못하고, 반대 기울기 쪽으로 넘어가게 되어 오히려 발산하는 현상입니다.
그렇다고 학습률을 작게 만드는 것이 무조건 좋은것이냐? 라고 생각하면 이 또한 단점이 있습니다. 위 함수는 이해를 위한 아주 단순한 2차함수이지만 실제 손실함수는 우리가 시각화 할수 없는 복잡한 함수이고 연산량이 훨씬 많습니다. 2차원인 단순한 함수에서만 확인해도 왼쪽 그래프가 훨씬 점이 많이 찍히는 것을 볼 수 있는데요, 이는 곧 기울기를 계산하고, $W$를 갱신하는 연산이 그만큼 더 많이 수행된다는 것을 의미합니다. 따라서 학습률이 너무 작다면 학습에 시간이 오래걸리고 연산량이 올라간다는 단점이 있습니다.
그리고 학습률이 작다면 한 가지 더 큰 문제가 발생합니다. 학습률이 너무 작다면 Local minimum에 빠질 수 있다는 문제가 발생합니다.
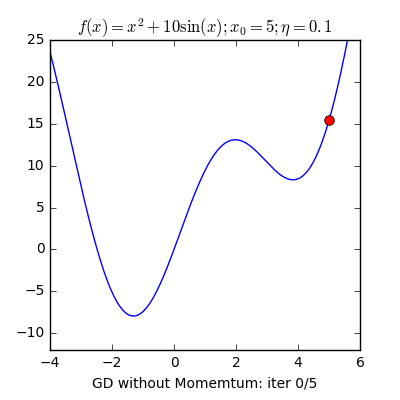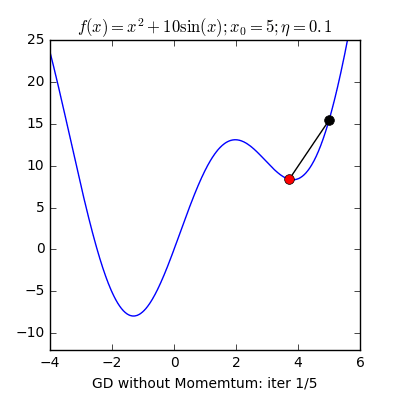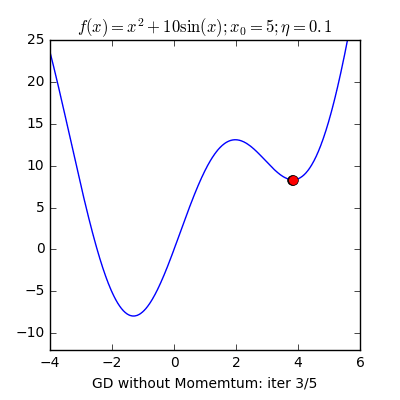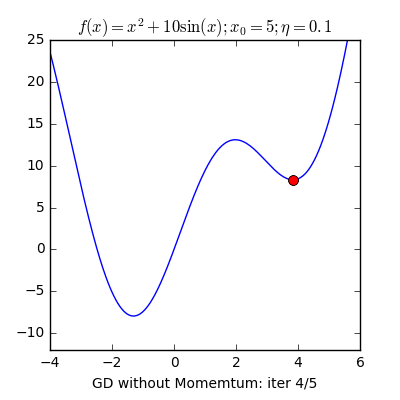
Local minimum(지역 최솟값)이란 이름 그대로 그 근방에서 최소인 지점을 말합니다. 우리는 전체 손실함수의 최소인 Global minimum 을 찾는 것이 최종 목표입니다. 그러나 Learning rate가 너무 작다면 위 그래프처럼 왼쪽에 명백히 더 작은 최솟값이 있음에도 불구하고 오른쪽 같은 local minumum에 빠질 수 있다는 단점이 있습니다.
이 문제는 learning rate가 작을수록 더 많이 발생하는 문제는 맞지만, learning rate가 크다고해서 이런 문제가 항상 발생하지 않는 것은 아닙니다. 왜냐하면 그레디언트 값 $ \nabla f(x_n) $ 값 자체가 작아지기 때문에 학습률과 무관하게 보폭이 작아지는 경우가 발생하기 때문입니다. 이는 Gradient descent의 고질적인 문제점 중 하나입니다. 찾은 해가 global minumum 임을 보장할 수가 없다는 것이죠. 수학적으로는 이를 최솟값이 아닌 극소점이나 안장점에 도달하게 된다고 표현합니다. 또한 이러한 문제 때문에 초기위치에 따라 결과가 달라지는 문제도 발생하게 됩니다.
이를 최대한 해결하기 위해 모멘텀(Momentum) 이라는 개념을 도입하게 되는데, 이는 추후 다른 포스팅에서 (아마 옵티마이저 포스팅)에서 다뤄보도록 하겠습니다.

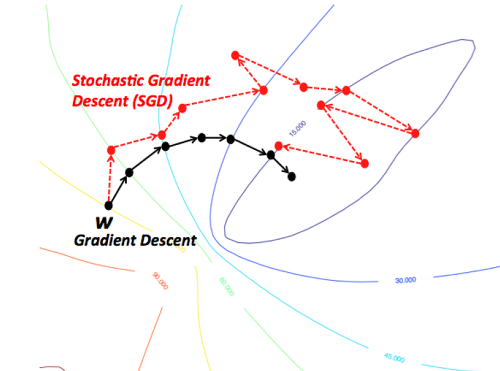
또한 위 식을 통해 Loss Function을 계산할 때 전체 Train set을 사용하는 것을 Batch Gradient Descent 라고 합니다. 그러나 이렇게 계산을 할 경우 한 번 계산할 때마다 전체 데이터에 대한 Loss Function을 계산해야 하기 때문에 너무 많은 계산량을 필요로 합니다. 이를 방지하기 위해 일반적으로 Stochastic Gradient Descent (SGD) 라는 방법을 사용합니다. 이 방법은 Loss Function 을 계산할 때 전체 데이터(Batch) 대신 조그만 데이터의 모음(mini-batch)에 대해서만 손실 함수를 계산합니다. 이 방법은 Batch Gradient Descent 보다 정확도는 떨어질 수 있지만 여러 번 반복할 경우 보통 batch의 결과와 유사하게 수렴합니다.
SGD 또한 추후 포스팅에서 다른 알고리즘과 비교하며 자세히 다룰 예정입니다. SGD 라는 용어를 앞으로 많이 접하게 되기 때문에 간략히 소개만 하고 넘어가도록 하겠습니다.
Gradient Descent 구현
지난 번 포스팅에서 Graidnet 에 대해 배웠고, 간단히 수치미분으로 구현도 해보았습니다. 이 코드를 그대로 사용하면 Gradient Descent 의 구현은 정말 간단합니다.
import numpy as np
def numerical_gradient(f, x):
h = 1e-5
grad = np.zeros_like(x) # x와 같은 형상의 배열 생성
for i in range(x.size):
temp = x[i]
# f(x+h) 계산
x[i] = temp + h
fxh1 = f(x)
#f(x-h) 계산
x[i] = temp - h
fxh2 = f(x)
grad[i] = (fxh1-fxh2) / (2*h)
x[i] = temp # 값 복원
return grad지난 포스팅에서 구현해보았던 수치미분 방식으로 구한 gradient 함수입니다. 경사 하강법은 각 점에서 그레디언트를 구하고, 그를 learning rate 랑 곱해서 빼는 것을 원하는 만큼 반복만 하면 됩니다.
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
x_history = []
for i in range(step_num):
x_history.append( x.copy() )
grad = numerical_gradient(f, x)
x -= lr * grad
return x, np.array(x_history)$f$는 최적화 하려는 함수, 실제 학습에서는 손실함수가 되겠죠. lr은 학습률, step_num 는 반복 횟수를 의미합니다. 함수의 기울기를 지난 번 구현했던 numerical_gradient(f,x)로 구하고 그 기울기에 학습률을 곱한 값을 뺀 값을 history 에 계속 append 합니다. 그리고 마지막에 원래의 $x$와 history를 return 하는 것이죠.
import matplotlib.pylab as plt
def function1(x):
#return x[0]**2 + x[1]**2
return np.sum(x**2)
init_x = np.array([-3.0, 4,0]) # 초기위치값 (-3, 4)
x, x_history = gradient_descent(function1, init_x, lr = 0.1, step_num = 20)
# 파란 점근선 표시
plt.plot( [-5, 5], [0, 0], '--b')
plt.plot( [0, 0], [-5, 5], '--b')
# history 의 (0열 원소(x좌표), 1열 원소(y좌표))
plt.plot(x_history[:,0], x_history[:,1], 'o')
plt.xlim(-3.5, 1)
plt.ylim(-1, 3.5)
plt.xlabel("X0")
plt.ylabel("X1")
plt.show()$ f(x_0, x_1) = x_0^2 + x_1^2 $ 의 함수에 대하여 gradient descent 를 적용하는데 그 과정에서 지나간 지점들을 표현한 코드입니다.

신경망에서의 기울기
간단한 $2 \times 3$ 신경망을 예로 실제로 기울기를 구하는 코드입니다. 우선 신경망 코드부터 확인해보겠습니다.
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포로 초기화
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss먼저 __init__ 을 통해 $W$를 랜덤한 $2 \times 3$으로 초기값을 초기화 합니다. predict는 가중치와 입력값을 곱하는 것입니다. 행렬곱을 통해 출력을 내보내는 것이죠.
손실함수는 loss 를 통해 정의되는데 이 때 softmax와 cross_entropy_error 는 지난 번에 정의한 것을 가져와 사용합니다. 의미만 확인해보면 pridict를 통해 계산된 결과가 $z$ 이 되는 것이고, 계산된 결과를 softmax 라는 activation function 을 거친 값을 $y$라고 놓는 것입니다. 그러면 $y$는 예측값이 될 것이고 $t$는 정답을 말합니다. 이 둘 사이의 차이에 대한 크로스 엔트로피를 계산하여 loss 로 정의하고 loss 를 반환하는 함수입니다.
간단한 숫자를 넣어서 dW를 구해보는 나머지 코드입니다.
x = np.array([0.6, 0.9]) # 입력 데이터
t = np.array([0, 0, 1]) # 정답 레이블
net = simpleNet() # 인스턴스 생성
f = lambda w: net.loss(x, t) # loss(손실함수) 반환
dW = numerical_gradient(f, net.W) # 손실함수는 2*3, dW 또한 2*3이 된다.
print(dW)
새로운 함수를 정의할 때 def 대신 짧은 함수라면 lambda 문법이 더 편합니다. 위 람다 코드는 아래와 동일한 의미입니다.
def f(W):
return net.loss(x,t)이제 신경망의 기울기를 구해냈다면, 위에서 배운 수식대로 이를 이용해 학습률을 곱하고, 원래의 가중치에서 빼는 방식으로 가중치 매개변수를 갱신하면 그 과정이 곧 학습입니다. 다음 포스팅에서 이어서 2층 신경망을 대상으로 전체적인 학습 과정을 구현해보도록 하겠습니다.

Reference :
http://shuuki4.github.io/deep%20learning/2016/05/20/Gradient-Descent-Algorithm-Overview.html
https://ai.plainenglish.io/whats-gradient-descent-with-momentum-a696d765f9b9
https://www.analyticsvidhya.com/blog/2021/07/understanding-the-what-and-why-of-gradient-descent/
https://github.com/WegraLee/deep-learning-from-scratch
밑바닥부터 시작하는 딥러닝 (저자 : 사이토 고키 / 번역 : 이복연 / 출판사 : 한빛미디어)
'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 역전파 ( Backward-propagation ) (0) | 2023.08.21 |
|---|---|
| [DL] 학습 알고리즘 구현 ( 2층 신경망 ) (0) | 2023.08.18 |
| [DL] 수치 미분 ( Numerical differentiation ) (0) | 2023.08.11 |
| [DL] 정보 엔트로피 ( Information Entropy ) (0) | 2023.08.07 |
| [DL] 손실 함수 ( Loss function ) (0) | 2023.08.03 |