앞선 포스팅에서 다루었던 내용들을 종합하여 간단한 구조의 신경망 학습을 전체적으로 구현해보는 포스팅입니다. 구현 하기 전 신경망 학습의 절차에 대해 간단히 확인해보면 아래와 같습니다.
- 미니배치 - 훈련 데이터의 일부를 무작위로 가져와 학습
- 기울기 산출 - 각 가중치 매개변수의 기울기를 구함 ( 손실함수 값을 줄이기 위해 )
- 매개변수 갱신 - 가중치 매개변수를 학습률과 기울기의 곱을 뺌으로써 갱신
- 반복 - 1~3 반복
2층 신경망 클래스를 구현하는 것부터 시작됩니다.
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x : 입력 데이터, t : 정답 레이블
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, W2.T)
dz1 = sigmoid_grad(a1) * da1
grads['W1'] = np.dot(x.T, dz1)
grads['b1'] = np.sum(dz1, axis=0)
return grads
전체적인 코드는 길어보이지만 새로운 내용은 거의 없습니다. 부분적으로 이를 해석해봅시다.
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)이전 SimpleNet 에서도 있었던 __init__ 입니다. 앞으로 어떤 클래스를 다루어도 pytorch 에서도 동일한 이름인 __init__ 을 사용합니다. 초기값을 지정하는 역할, 혹은 상위 클래스를 상속 받는 역할 등을 __init__ 함수 내에서 구현합니다.
params 는 신경망의 매개변수를 보관하는 딕셔너리 변수(인스턴스 변수) 입니다. params['W1'] 는 첫번째 층의 가중치, params['b1']은 첫번째 층의 바이어스, params['W2'] 는 두번째 층의 가중치, params['b2']는 두번째 층의 바이어스를 의미합니다.
weight_init_std 는 함수의 인자로 전달되는 상수이고, np.random.randn(입력데이터의 크기, 은닉층의 크기) 를 통해 입력데이터의 크기$\times$은닉층의 크기 의 표준정규분포에 비례하는 랜덤한 가중치 초기값을 할당하는 겁니다.
바이어스는 np.zeros를 통해 은닉층의 크기에 맞게 만들어 줍니다.
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return ypredict 는 다른 말로 순전파 과정이라고도 생각할 수 있습니다. 임시 변수 W1, W2에 인스턴스의 가중치 값을 받아오고, b1, b2에 바이어스 값을 받아오고 입력 데이터에 대해 맨 처음에 배웠던 연산을 수행하는 겁니다.
$$ A^{(1)} = XW^{(1)} + B^{(1)} $$
연산 결과가 a1 인 것이고, 이를 활성함수를 통과시킨 값을 z1 이라 합니다. 즉 z1은 첫번째 층을 통과한 출력값이자 2번째 층의 입력값이 다시 되겠죠? 다시 a2를 계산하고, 마지막 층이므로 sigmoid 대신 softmax 를 통과시킨 값을 y라 하고 y를 반환하는 것입니다.
만약 이 내용이 헷갈리거나 이해가 안 가시면 아래 포스팅을 복습하고 오시면 이해가 되실겁니다.
[DL] 인공 신경망 ( Artificial neural network, ANN ) - Forward Propagation
인공신경망이란? 인공 신경망 ( Artificial neural network, ANN ) 이란 앞서 배웠던 퍼셉트론과 활성 함수의 아이디어를 결합한 모델을 뜻합니다. 즉 인공신경망은 시냅스의 결합으로 네트워크를 형성한
songsite123.tistory.com
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracyloss 는 손실함수를 구합니다. 예측 값을 받아서 실제 정답과의 크로스 엔트로피값을 반환합니다. 물론 이 때 cross_entropy_error 는 다른 파일이나 바깥에 구현이 되어 있어야합니다.
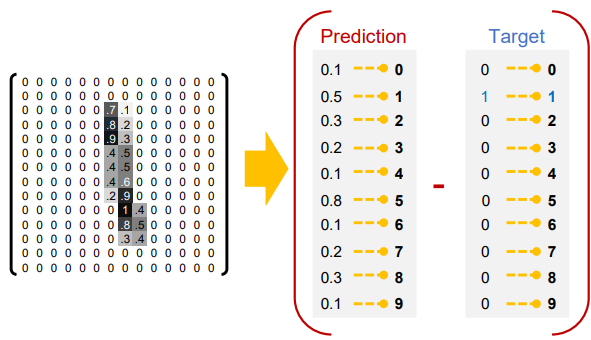
accuracy 는 정확도를 출력하는 함수입니다. 입력 데이터와 정답 데이터를 인수로 넣고 마찬가지로 계산 결과를 y로 놓습니다. 이 때 argmax 를 통해 값이 가장 큰 인덱스를 반환합니다. 이 때 axis = 1 이면 행을 기준으로 체크하고 axis = 0 이면 열을 기준으로 체크합니다. 이 네트워크를 통해 학습시킬 데이터가 MNIST 데이터이기 때문에 뉴럴 네트워크를 거쳐서 나오게 된 0~9에 대한 확률벡터가 나오게 될텐데, argmax를 통해 가장 확률값이 높은 인덱스를 뽑으면 그것이 곧 우리가 예측하려 했던 숫자와 같기 때문에 예측한 숫자가 나옵니다.
그럼 t에 대해서는 왜 argmax를 하지? 라고 생각해보면 정답 레이블은 정답만 1로 처리하고 나머지는 0으로 처리하는 one-hot vector 의 형태를 가지고 있기 때문에 argmax를 취하면 정답이 나오게 됩니다.
이 둘을 비교하여 둘이 같은 값이라면 하나씩 더하는 것이죠. np.sum 을 통해 각각의 행에 대해 모두 수행한다음에 이것을 x.shape[0], 즉 행의 총 개수로 나누면 이는 곧 맞은 데이터 / 전체 데이터 가 되어 정확도를 나타내게 됩니다.
그 이후 정의되는 numerical_gradient(self, x, t) 는 수치 미분 방식으로 매개변수의 기울기를 계산하는 메서드이고, gradient(self, x, t) 는 조금 더 업그레이드 된, 오차역전파법으로 기울기를 구하는 메서드입니다. 오늘의 포스팅에서는 numerical_gradient(self, x, t)를 사용하여 학습 과정을 구현할 것이고, 다음 포스팅에서 오차 역전파법에 대해 다루면서 gradient(self, x, t)에 대해 자세히 설명할 예정입니다.
미니배치 (mini-batch) 학습 구현 - 수치미분
위의 TwoLayerNet 클래스와 MNIST 데이터셋을 사용해 학습울 수행해봅시다.
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
# 하이퍼파라미터
iters_num = 10000 # 반복 횟수를 적절히 설정한다.
train_size = x_train.shape[0]
batch_size = 100 # 미니배치 크기
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 1에폭당 반복 수
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
# 미니배치 획득
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
#grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 학습 경과 기록
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 1에폭당 정확도 계산
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))위 코드가 학습의 전체적인 코드입니다. 신경망과 마찬가지로 부분적으로 의미를 파악해보도록 하겠습니다.
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 뉴럴 네트워크 인스턴스 생성
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)데이터세트를 읽어옵니다. normalize 는 각 픽셀의 밝기가 0 ~ 255 로 표현되는 것을 255로 나누어 0 ~ 1 사이의 값으로 읽어들인다는 의미입니다.
그 다음으로 인스턴스를 생성합니다. 입력층의 뉴런 개수는 784개, 은닉층의 뉴런 개수는 50개, 출력 뉴런의 개수는 10개인 인스턴스를 생성한 겁니다. weight_init_std 는 따로 설정해주지 않았지만 디폴트 값이 선언되어 있기 때문에 따로 쓰지 않으면 클래스 정의에서 설정했던 디폴트 값을 사용하게 됩니다.
# 하이퍼파라미터
iters_num = 10000 # 반복 횟수를 적절히 설정한다.
train_size = x_train.shape[0]
batch_size = 100 # 미니배치 크기
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 1에폭당 반복 수
iter_per_epoch = max(train_size / batch_size, 1)사용자가 직접 지정해주는 변수들인 하이퍼 파라미터입니다. 반복 횟수, x_train.shape[0] 은 데이터의 개수를 의미합니다. 이전 MNIST 포스팅에서 다룬 내용입니다. 전체 반복횟수는 1만회로 지정해주었고, 이는 epoch와 다른개념이니 유의해야합니다.
[DL] MNIST ( Modified National Institute of Standards and Technology database )
이번 포스팅은 MNIST 데이터셋을 이용해 직접 신경망의 순전파를 확인해보고, 일종의 실습을 하는 포스팅입니다. MNIST 는 대표적인 기계학습 데이터셋으로 0부터 9까지의 숫자 이미지로 구성된 데
songsite123.tistory.com
60000개의 데이터 중 미니 배치의 사이즈를 100으로 지정해주고, 학습률 또한 0.1로 지정해줍니다. 그리고 후에 loss랑 정확도를 저장할 리스트들을 선언하고, 1 epoch 당 몇번의 반복이 진행되는지를 max(train_size/batch_size, 1) 로 구해줍니다. 만약 미니 배치의 크기가 훈련 데이터의 크기보다 크다면 분할되지 않고 그냥 전체 데이터가 1번 반복 학습되겠죠? 만약 미니 배치의 크기가 훈련 데이터보다 더 작다면 그에 맞게 max 는 train_size/batech_size 가 저장됩니다.
MNIST 데이터 6만개에 대해 미니 배치의 사이즈를 100으로 지정하면 iter_per_epoch = 60000 / 100 = 600 이 됩니다.
for i in range(iters_num):
# 미니배치 획득
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 계산
# grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 학습 경과 기록
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 1에폭당 정확도 계산
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))반복횟수 만큼 for문이 돌아가고, batch_mask=np.random.choice(a, b) 란 a 미만으로 b개를 샘플링 하는 것을 의미합니다. 즉 6만개의 데이터 중에서 랜덤한 100개를 뽑겠다는 의미가 됩니다. 즉 batch_mask 는 리스트가 되는데, x_batch, t_batch 에 아까의 데이터들을 슬라이싱하라는 의미가 됩니다.
그 다음은 기울기 계산 부분입니다. 이는 전 포스팅에서 설명을 했던 내용이죠. 주석처리 부분이 수치미분으로 그레디언트를 구하는 코드, 그 밑은 오차역전파법으로 그레디언트를 구하는 방법을 의미합니다. 수치미분보다 오차역전파법을 적용한 그레디언트를 구하는 코드가 훨씬 빠르기 때문에 이번 학습에서는 아래를 선택하도록 하겠습니다. 실제 이 둘의 구현은 무엇을 적용하느냐에 따라 달라집니다. 수치미분으로 계산하면 계산량이 너무 많기 때문에 시간이 굉장히 오래 걸립니다.
아무튼 기울기를 구하면 grad를 반환합니다. 이는 딕셔너리 타입으로 정의되어 있고 아래와 같은 형태를 가집니다.
$$ \text{grad} = \{ W1:\dfrac{\partial L}{\partial W_1}, b1:\dfrac{\partial L}{\partial b_1}, W2:\dfrac{\partial L}{\partial W_2}, b2:\dfrac{\partial L}{\partial b_2} \}$$
이 때 당연히 저 편미분 값들은 모두 numpy 객체로 이루어져 있습니다. 대략적인 형태가 위처럼 딕셔너리 형태로 묶여있다는 것이죠.
그 다음의 매개변수 갱신 코드를 보면 따라서 딕셔너리의 키들에 대해 반복이 됩니다. 키가 W1인 경우 그레디언트 W1과 학습률을 곱한 값을 빼주는 것이죠. params 가 기억이 안나면 맨 위로 올라가셔서 확인해보고 오세요.
매개변수 갱신이 끝나면 loss 를 계산합니다. 이 때는 정의된 loss 함수를 사용하고, 이 때 x_batch 와 t_batch 를 비교하여 Loss 에 대한 결과를 받는 것이죠. loss 함수 내부적으로 크로스 엔트로피를 계산하여 반환합니다.
그 다음으로 i는 몇번째 epoch 이냐를 의미합니다. 60000개의 데이터를 100개씩 끊어서 학습하고 있으므로 총 600번이 반복되어야 1 epoch 가 끝나는 겁니다. 그런데 우리가 반복횟수를 10000번으로 했으므로 600, 1200, 1800, ... , 9600 까지만 if문이 수행될겁니다.
if 문 내에서는 train_acc와 test_acc 를 구해서 이를 출력해줍니다. 이 학습을 수행하게 되면 그래서 출력문은 총 17번(i 가 0일 때도 출력)만 나타나게 됩니다.

# 그래프 그리기
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()그 다음은 matplotlib을 통해 train 과 test 정확도를 출력해주는 코드입니다. 출력 결과는 아래와 같습니다.

아주 단순한 2층 신경망 만으로도 10000번의 미니배치 반복 학습, 대략 16 epoch 정도 학습을 진행했는데 벌써 정확도가 90% 넘게 나타나는 것을 확인할 수 있습니다. 또한 훈련 데이터와 테스트 데이터에서 차이가 없으므로 오버피팅이 일어나지 않았다는 것도 유추할 수 있습니다.
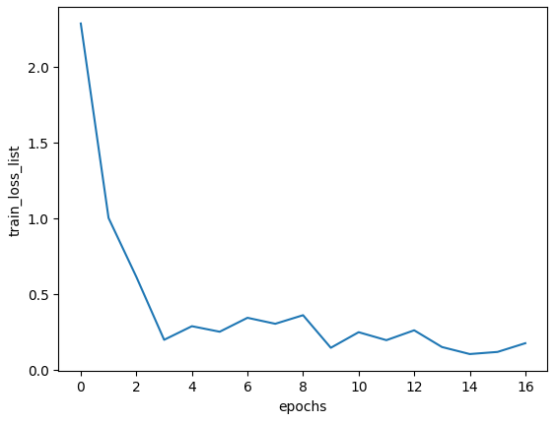
또한 앞으로 자주 보게 될 코드로 정확도가 아닌 Loss 를 체크하고 출력하는 코드도 확인해봅시다. if 문 내와 출력만 조금 바꿔주면 됩니다.
# 1에폭당 정확도 계산
if i % iter_per_epoch == 0:
train_loss_list.append(loss)
print("train loss" + ", " + str(loss))
# 그래프 그리기
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_loss_list))
plt.plot(x, train_loss_list, label='train_loss_list')
plt.xlabel("epochs")
plt.ylabel("train_loss_list")
plt.show()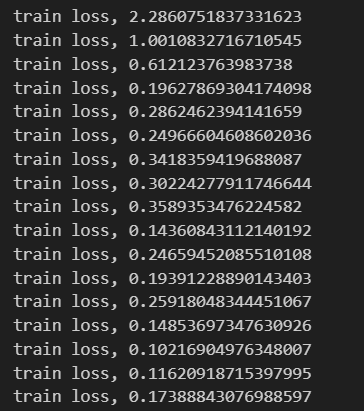
오늘 포스팅은 학습에서 오차역전파로 기울기를 갱신하는 gradient 함수에 대한 부분은 설명하지 않았습니다. 이는 역전파에 대한 내용을 포스팅 한 이후에 다룰 예정입니다. 감사합니다.

Reference :
https://github.com/WegraLee/deep-learning-from-scratch
밑바닥부터 시작하는 딥러닝 (저자 : 사이토 고키 / 번역 : 이복연 / 출판사 : 한빛미디어)
'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 역전파를 이용한 2층 신경망 학습 구현 (0) | 2023.08.22 |
|---|---|
| [DL] 역전파 ( Backward-propagation ) (0) | 2023.08.21 |
| [DL] 경사 하강법 ( Gradient Descent ) (0) | 2023.08.17 |
| [DL] 수치 미분 ( Numerical differentiation ) (0) | 2023.08.11 |
| [DL] 정보 엔트로피 ( Information Entropy ) (0) | 2023.08.07 |