활성 함수란? ( Heaviside, Sigmoid, ReLU )

지난 포스팅에서 살펴본 퍼셉트론의 구조에 대한 그림을 다시 살펴보면 오른쪽에 활성 함수(Activation Function) 이라는 것이 있습니다. 다시 한 번 퍼셉트론을 나타낸 수학적 수식을 살펴보면 아래와 같습니다.
$$ y=\begin{cases}0,\ \quad \ \ \ b+w_1x_1+w_2x_2\ \le 0\\1,\quad \ \ \ \ b+w_1x_1+w_2x_2\ >0\end{cases} \quad \quad ↔ \quad \quad y = h(w_1x_1+w_2x_2+b) $$
이 때 $h$ 는 헤비사이드 함수(Heaviside function) (= 단위 계단 함수(unit step function)) 을 뜻합니다.
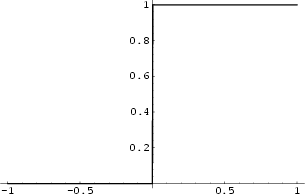
$$ h\left(x\right)=\begin{cases}0,\ \ \ \ x\le 0\\1,\ \ \ \ x>0\end{cases} $$
신호 처리와 같은 분야에서는 $x=0$ 일 때 $ h(x) = \dfrac{1}{2} $ 로 놓기도 하지만 우선은 위 정의를 따르는 $h$를 사용한다고 가정하겠습니다. 즉 unit step function, 단위 계단 함수로 퍼셉트론을 모델링을 할 수 있습니다.
이처럼 입력 신호의 총합을 출력 신호로 변환하는 함수를 일반적으로 활성 함수(Activation function) 라 합니다.
퍼셉트론 같은 단순한 구조는 헤비사이드 함수를 활성 함수로 사용할 수 있지만, 더 나아가 신경망으로 사용하기 위해서는 다른 활성 함수를 사용해야만 합니다. 지난 퍼셉트론 포스팅에서 보았듯 퍼셉트론만으로는 당장 XOR 게이트조차 구현할 수 없기 때문입니다. 이에 대한 좀 더 자세한 이유는 매개변수 값을 조정하는 학습이 미분을 기반으로 이루어지게 되는데, 헤비사이드 함수는 벌써 $x=0$에서의 미분이 불가능하고 나머지 영역에서 모두 미분계수가 0이기 때문에 학습이 불가능한 구조입니다. 즉, 헤비사이드 함수의 미분이 델타 함수가 나오기 때문에 신경망에서 사용할 활성 함수로는 적합하지 않습니다.
(델타 함수에 대해 모르시는 분들은 아래 포스팅을 참고해주세요)
Dirac Delta Function[디렉 델타 함수]
디렉 델타 함수, 단위 임펄스 함수에 대해 조금 자세하게 알아보겠습니다. 통상적으로 디렉 델타 함수라고 ...
blog.naver.com
또한 다른 활성 함수를 사용하더라도 가중치가 곱해진 입력 신호의 총합을 계산하고, 그 합을 활성 함수에 입력해 출력을 구하는 메커니즘은 동일하게 유지됩니다.
따라서 다른 함수들을 활성 함수로 사용하게 되는데 가장 대표적인 함수가 시그모이드 함수(sigmoid function) 입니다.

$$ y=\frac{1}{1+e^{-x}} $$
이 함수의 개형에 대해서는 고등학교 수준의 미적분 지식으로 쉽게 유추할 수 있습니다. $x$가 커질수록 $e^{-x}$ 는 지수적으로 작아지기 때문에 $\dfrac{1}{1+0}$ 과 같은 값을 가집니다. 따라서 $y=1$을 점근선으로 가집니다. $x=0$일 때는 $e^{-0}=1$ 이기 때문에 $y=0.5$를 지나고, $x$가 작아진다면 $e^{-x}$는 지수적으로 큰 값이 되기 때문에 $\dfrac{1}{1+∞ }$ 에 가까운 값으로 $y=0$이라는 점근선을 가지게 됩니다.
이 함수는 미분해도 다시 시그모이드의 함수로 구할 수 있는 꼴이 나온다는 특징이 있습니다.

신경망에서 가장 대표적으로 배우는 활성 함수가 시그모이드 함수이지만, 다른 비선형 함수를 사용할 수도 있습니다. 그 중 많이 사용되는 함수를 하나 더 소개하려 하는데, 바로 ReLU 함수 (Rectified Linear Unit function)입니다.
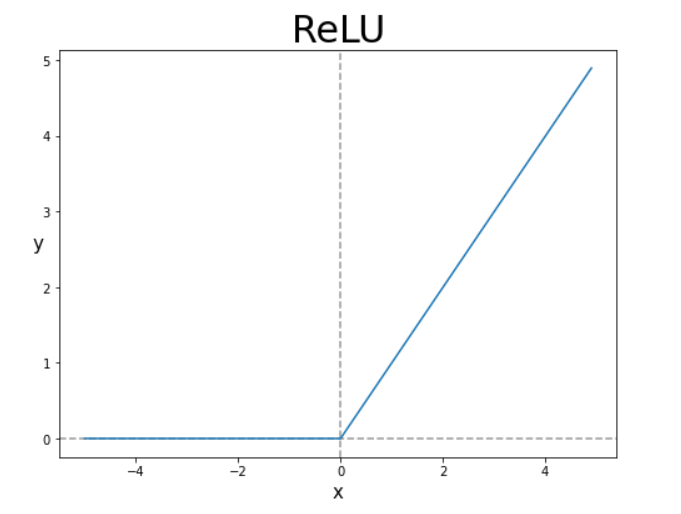
$$ h\left(x\right)=\begin{cases}0,\ \ \ \ x\le 0\\x,\ \ \ \ x>0\end{cases} $$
ReLU 는 입력이 0을 넘으면 그 입력을 그대로 출력하고, 0 이하이면 0을 출력하는 함수입니다. ReLU 의 이름부터 알 수 있는데, 정류된 선형 신호를 뜻합니다.
이 밖에도 다른 함수들을 활성 함수로 사용할 수 있는데, 이 때 활성 함수는 무조건 비선형 함수를 사용해야 합니다. 비선형 함수가 아닌 선형 함수를 활성 함수로 사용하면 신경망에서의 층을 깊게 하는 작업, 즉 은닉층을 늘리는 작업이 의미가 없어지기 때문입니다.
선형 함수를 활성 함수로 사용하는 노드를 여러번 통과한다는 것은 그 함수에 입력이 여러번 중첩되어 들어간다는 것입니다. 즉 $y=f(f(f(x))) $ 와 같은 수식으로 신경망을 모델링할 수 있습니다. 이 때 $f$가 만약 선형함수라면 이는 $y=g(x) $ 라는, 계수만 다른 선형 함수로 모델링할 수 있습니다. 즉 선형 함수를 활성화 함수로 사용하는 경우 아무리 층을 늘려도 단층 네트워크보다 성능을 늘릴 수가 없습니다.
단층 네트워크의 가장 대표적인 단층 퍼셉트론으로는 XOR 문제도 풀지 못했습니다. 그만큼 층을 깊게 하는 작업은 좀 더 어렵고 복잡한 작업을 수행하는데 있어 필수적인 요소기 때문에 비선형 함수를 활성 함수로 사용해야만 딥러닝 같은 복잡한 작업을 할 수 있습니다.
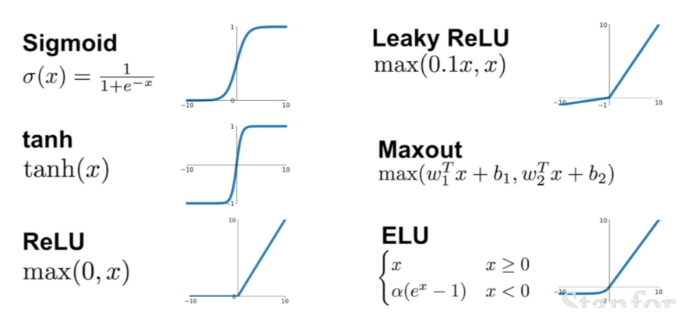
그 밖에도 여러 활성 함수가 사용되고 있습니다. 이처럼 다양한 활성 함수들이 있는데, 각각마다 특징이 있고 장단점이 있기 때문에 상황에 맞춰, 즉 내가 원하는 출력이 어떤 형태의 데이터인지 입력으로 쓰는 데이터들이 어떤 특징이 있는지와 같은 상황에 맞춰 활성함수를 골라서 사용하게 됩니다.
Heaviside, Sigmoid, ReLU 파이썬 구현
import numpy as np
import matplotlib.pylab as plt
def heaviside(x):
return np.array(x > 0, dtype=np.int)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y1 = heaviside(x)
y2 = sigmoid(x)
y3 = relu(x)
plt.plot(x, y1, label="Heaviside")
plt.plot(x, y2, label="Sigmoid")
plt.plot(x, y3, label="ReLU")
plt.ylim(-0.1, 1.1)
plt.legend()
plt.show()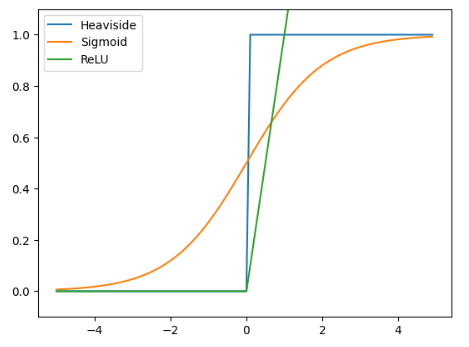

Reference :
밑바닥부터 시작하는 딥러닝 - 사이토 고키
https://ok-lab.tistory.com/151
https://ko.wikipedia.org/wiki/%EC%8B%9C%EA%B7%B8%EB%AA%A8%EC%9D%B4%EB%93%9C_%ED%95%A8%EC%88%98
'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 정보 엔트로피 ( Information Entropy ) (0) | 2023.08.07 |
|---|---|
| [DL] 손실 함수 ( Loss function ) (0) | 2023.08.03 |
| [DL] MNIST ( Modified National Institute of Standards and Technology database ) (0) | 2023.07.31 |
| [DL] 인공 신경망 ( Artificial neural network, ANN ) - Forward Propagation (0) | 2023.07.27 |
| [DL] 퍼셉트론 ( Perceptron ) (0) | 2023.07.25 |