인공신경망이란?
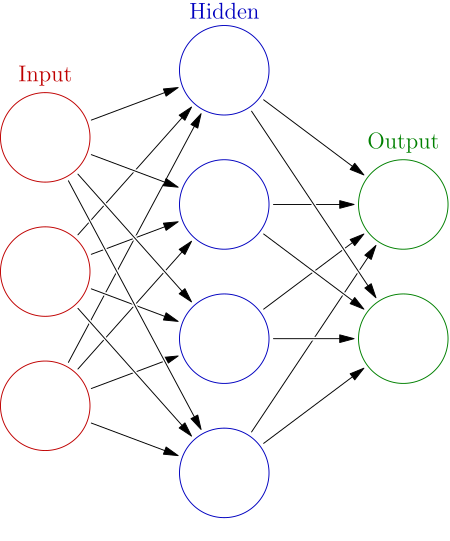
인공 신경망 ( Artificial neural network, ANN ) 이란 앞서 배웠던 퍼셉트론과 활성 함수의 아이디어를 결합한 모델을 뜻합니다. 즉 인공신경망은 시냅스의 결합으로 네트워크를 형성한 인공 뉴런(노드)가 학습을 통해 시냅스의 결합 세기를 변화시켜 문제 해결 능력을 가지는 모델을 전반적으로 지칭하는 단어입니다.
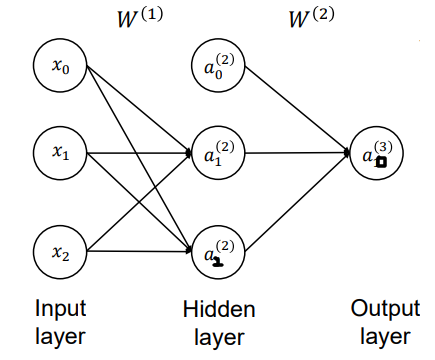

위 같은 인공신경망은 행렬을 통해 구현할 수 있습니다. 입력층을 Input layer, 중간의 은닉층을 Hidden layer, 출력층을 Output layer 라고 부릅니다. 이 때 $x_i, a_j^{(i)}, W^{(j)} $ 들이 의미하는 바는 아래와 같습니다.
$$ a_j^{(i)} : \text{“Activation" of the i-th unit in the j-th layer}$$
$$ W^{(j)} : \text{“Weight Matrix" mapping from the j-th layer to the (j+1)-th layer} $$
왼쪽 그림은 0부터 시작하긴 하는데, 통상적으로는 오른쪽 그림처럼 unit은 1부터 시작하고, input layer 를 0으로 시작하는 방식을 사용하게 됩니다.
입력은 가중행렬에 의해 연산되어 가중합을 구하게 되고, 그 가중합을 활성 함수의 입력으로 넣어서 구하는 것이 곧 출력입니다. 이 과정을 Forward propagation(순전파) 이라고 부르며 조금 더 자세하게 단계별로 알아보고, 간단한 3중 신경망을 구현해보도록 하겠습니다.
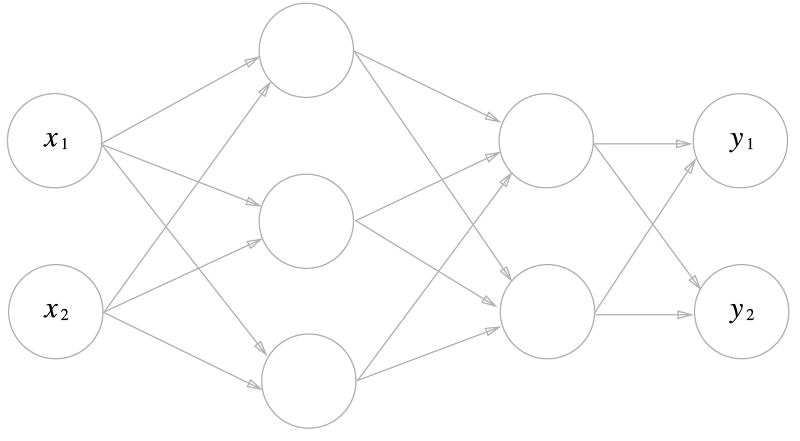
입력이 $x1, x2$로 2개, 출력이 $y_1, y_2$ 로 2개인 3중 신경망입니다. 첫번째로 입력층에서 1층으로 신호가 전달됩니다.
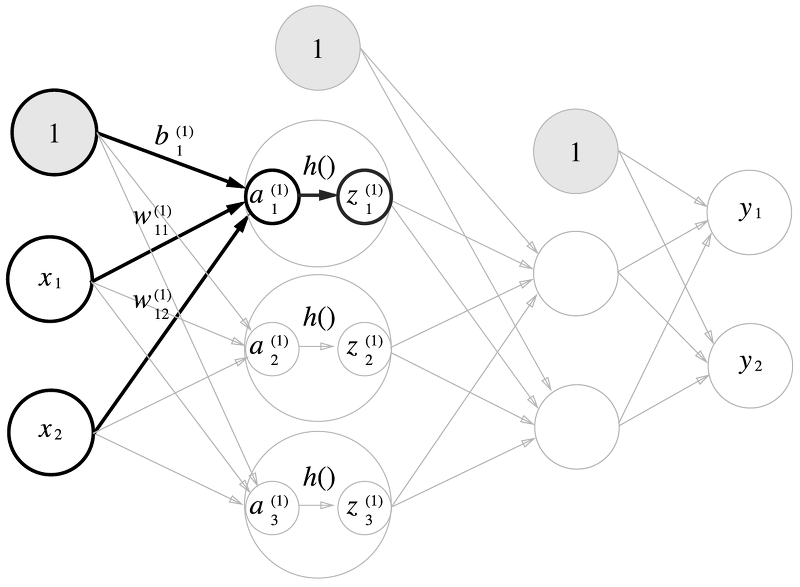
입력은 2개이지만 앞서 배웠던 활성함수나, 퍼셉트론에서 편향(바이어스)가 추가되는 것을 배웠습니다. 각 층에서 바이어스가 추가되게 되는데 가중치의 아래첨자가 의미하는 것들은 왼쪽 숫자는 왼쪽의 노드 번호(출발노드번호), 오른쪽 숫자는 오른쪽 층의 노드 번호가 됩니다. 바이어스는 하나만 있는데 목적지만 가리킵니다. 위 사진은 아래 수식을 나타낸 그림입니다.
$$ z_1^{(1)}=h(a_1^{(1)} ) \quad , \quad a_1^{(1)}=w_{11}^{(1)} x_1+w_{12}^{(1)} x_2+b_1^{(1)} $$
첫 번째 노드에 대해서만 연산을 수행하지 않고, 한번에 모두 수행하는 연산을 하려면 행렬의 곱셈으로 나타내야 합니다.
$A^{(1)} = ( a_1^{(1)} \ \ a_2^{(1)} \ \ a_3^{(1)} ) $, $X=(x_1 \ \ x_2 ) $, $B^{(1)} = ( b_1^{(1)} \ \ b_2^{(1)} \ \ b_3^{(1)} )$, $ W = \left(\begin{matrix}w_{11}^{\left(1\right)}&w_{21}^{\left(1\right)}&w_{31}^{\left(1\right)}\\w_{12}^{\left(1\right)}&w_{22}^{\left(1\right)}&w_{23}^{\left(1\right)}\end{matrix} \right) $ 로 $A, X, B, W$ 행렬을 정의하면
$$ A^{(1)} = XW^{(1)} + B^{(1)} $$
와 같은 행렬식으로 입력층에서 1층으로 신호가 전달되고 계산되는 과정을 한번에 처리할 수 있습니다.
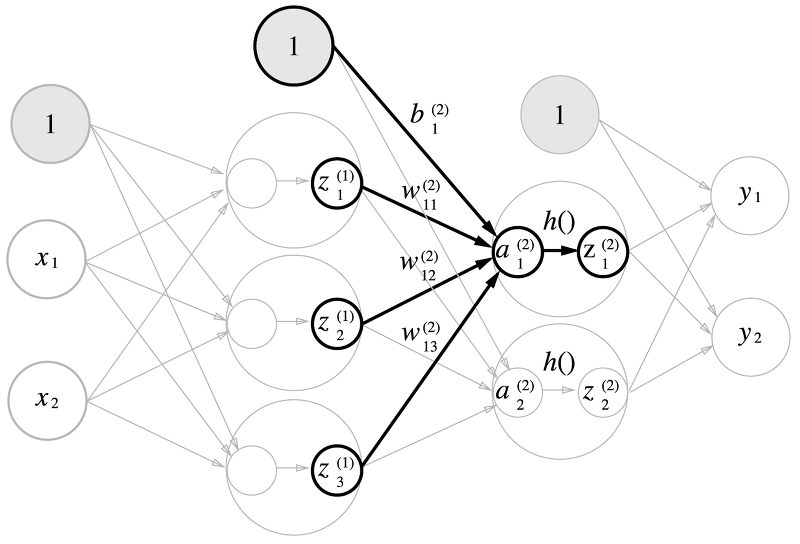
1층에서 2층으로의 신호 전달도 그렇게 구한 $a$들에 대해서 활성 함수의 입력으로 넣은 출력을 다시 다음 층의 입력으로 사용하게 됩니다. 완전히 동일한 작업입니다.
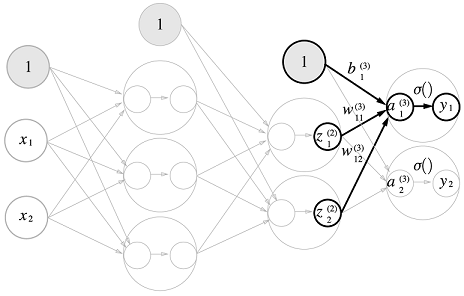
마지막으로 2층에서 출력층으로의 신호 전달입니다. 이 때도 $a$까지의 가중합은 행렬의 곱셈으로 연산처리가 되지만, 통과하는 함수가 시그모이드 활성 함수가 아닌, softmax 라는 함수를 통과하게 됩니다. σ 로 표현되어 있는 이 함수는 일반적인 벡터를 확률벡터로 변환하는 역할을 하는 함수입니다. 일반적으로 출력층에서 사용하는 활성함수는 회귀 문제인지, 분류 문제인지에 따라 달라지는데 회귀에는 보통 항등 함수를, 분류에는 보통 소프트맥스 함수를 사용합니다.

항등 함수(identity function) 은 이름 그대로 입력을 그대로 출력하는 함수입니다. 출력층에서 항등 함수를 사용한다는 것은 마지막 출력층에 들어온 입력 신호가 그대로 출력 신호가 되는 것을 뜻합니다. 분류에서 사용하는 소프트맥스 함수의 경우 아래 식을 따릅니다.
$$ y_k = \dfrac{e^{a_k}}{\sum_{i=1}^n e^{a_i}} $$
$n$은 출력층의 뉴런 수, $y_k$ 는 출력층의 노드 중 $k$번째 출력을 의미합니다. 즉 소프트맥스 함수의 분자는 입력 신호 $a_k$의 지수 함수, 분모는 모든 입력 신호의 지수합으로 구성됩니다.
소프트맥스 함수의 특징은 확률 벡터로 바꿔주기 때문에 각 함수의 출력을 확률로 생각할 수 있습니다. 각 뉴런에서의 모든 출력값은 0~1 사이의 값을 가지게 되고, 모든 출력층의 결과를 합하게 되면 1이 됩니다.
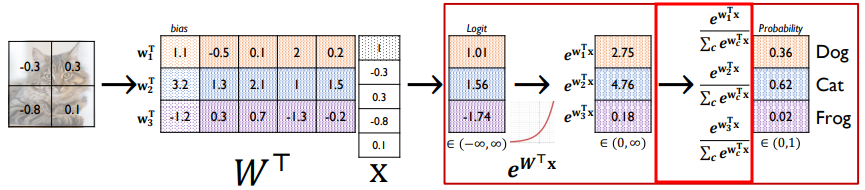
전체적인 Softmax Layer를 통해 어떤 이미지 분류기를 만든다면 위 같은 과정을 통해 softmax 함수가 적용됩니다. 빨간 박스 내부의 과정 중 내부 빨간 박스 안의 연산이 바로 softmax 함수를 통과하는 것이고, 그 앞은 가중합이 활성 함수로 입력되는 과정, 그리고 활성함수에서 나온 출력을 다시 소프트맥스 함수에 넣는 과정입니다. 표기가 좀 다른 것은 행렬식으로 나타내기 때문입니다.
위의 소프트맥스 함수 식을 그대로 파이썬으로 구현하려고 하면 오버플로우가 발생하게 됩니다. 왜냐면 지수의 나눗셈이 이루어지기 때문에 너무 큰 값은 inf로 처리되어 연산이 불안정해지기 때문입니다. 따라서 구현하기 위해서는 어느 정도 모양을 조작해야만 합니다.
$$ y_k = \dfrac{e^{a_k}}{\sum_{i=1}^n e^{a_i}} = \dfrac{Ce^{a_k}}{C\sum_{i=1}^n e^{a_i}} = \dfrac{e^{a_k+logC}}{\sum_{i=1}^n e^{a_i+logC}} = \dfrac{e^{a_k+C'}}{\sum_{i=1}^n e^{a_i+C'}} $$
위 식이 의미하는 것은 지수함수의 지수 내에서 어떤 임의의 값을 빼거나 더해도 값이 달라지지 않는다는 사실 입니다. 따라서 우리는 $C'$을 원하는 값으로 조정하여 지수함수의 지수가 너무 커지지않게 조절할 수 있고, 일반적으로 입력 신호 중 최댓값을 $C'$ 으로 많이 사용하여 빼는 식으로 사용합니다.
3층 신경망 구현
단계별로 알아보았던 내용을 코드로 구현한 내용입니다. 주석 처리로 위의 내용 중 어떤 부분인지 설명되어 있습니다.
import numpy as np
# 시그모이드 활성함수
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 소프트맥스 함수
def softmax(a):
c = np.max(a)
exp_a = np.exp(a-c) # 오버플로우를 막기 위해 입력 신호의 최댓값을 빼서 연산
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# 초기값 Weight matrix 및 바이어스 설정
def init_network():
network = {}
# 가중치 W1 은 2*3 행렬 -> 1*2 행렬과 2*3 행렬이 곱해져 1*3 형태의 첫번째 층 결과가 나타남
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
# 가중치 W2 은 3*2 행렬 -> 1*3 행렬과 3*2 행렬이 곱해져 1*2 형태의 두번째 층 결과가 나타남
network['W2'] = np.array([[0.1, 0.4], [0.5, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
# 가중치 W3 은 2*2 행렬 -> 1*2 행렬과 2*2 행렬이 곱해져 1*2 형태의 세번째 층 결과가 나타남
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
# 순전파 과정 forward 함수
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1 # 첫번째 층의 뉴런의 가중합을 계산 ( x과 W1의 행렬 곱 )
z1 = sigmoid(a1) # 활성 함수(시그모이드)를 통과하여 z1들을 구함
a2 = np.dot(z1, W2) # 두번째 층의 뉴런의 가중합을 계산 ( z1과 W2의 행렬 곱 )
z2 = sigmoid(a2) # 활성 함수(시그모이드)를 통과하여 z2들을 구함
a3 = np.dot(z2, W3) # 세번째 층의 뉴런의 가중합을 계산 ( z2와 W3의 행렬 곱 )
y = softmax(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
# 출력 결과 [0.43127497 0.56872503] -> 둘의 합이 1이 나온다(softmax 거쳤기 때문)최대한 주석을 자세하게 달아놨고, 아예 이 코드만 복붙해도 돌아가도록 전체 코드를 올렸으니 이해 안되는 부분은 위 그림과 함께 보시면 어려운 내용은 없으리라 생각됩니다. 혹시 이해가 안되거나 틀린 부분이 있으면 댓글로 남겨주세요. 감사합니다.

Reference :
밑바닥부터 시작하는 딥러닝 - 사이토 고키
https://www.deep-mind.org/2023/03/26/the-universal-approximation-theorem/
https://ko.wikipedia.org/wiki/%EC%9D%B8%EA%B3%B5_%EC%8B%A0%EA%B2%BD%EB%A7%9D
'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 정보 엔트로피 ( Information Entropy ) (0) | 2023.08.07 |
|---|---|
| [DL] 손실 함수 ( Loss function ) (0) | 2023.08.03 |
| [DL] MNIST ( Modified National Institute of Standards and Technology database ) (0) | 2023.07.31 |
| [DL] 활성 함수 ( Activation function ) (0) | 2023.07.26 |
| [DL] 퍼셉트론 ( Perceptron ) (0) | 2023.07.25 |