이번 포스팅은 MNIST 데이터셋을 이용해 직접 신경망의 순전파를 확인해보고, 일종의 실습을 하는 포스팅입니다. MNIST 는 대표적인 기계학습 데이터셋으로 0부터 9까지의 숫자 이미지로 구성된 데이터셋입니다.

MNIST의 이미지 데이터는
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
import pickle
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[3]
label = t_train[3]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 형상을 원래 이미지의 크기로 변형
print(img.shape) # (28, 28)
img_show(img)
'''
출력 :
1
(784,)
(28, 28)
'''만약 위 코드를 실행하는데 다음과 같은 오류가 뜬다면 Python Imaging Library(PIL) 모듈이 설치되지 않았기 때문입니다. 따라서 최신 버전의 pip를 설치하고 Pillow 라이브러리를 설치하면 오류가 발생하지 않습니다.
그리고 ime_show() 함수를 따로 정의한 이유는, 우리가 이미지를 보려면 784개의 1차원 배열로 저장된 데이터를 다시금
matplotlib 을 사용해서 데이터를 확인할 수도 있습니다.
import matplotlib.pyplot as plt
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=False, one_hot_label=False)
plt.figure()
plt.imshow(x_train[0][0])
plt.colorbar()
plt.show()
plt.figure(figsize = (10,10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[i][0], cmap=plt.cm.binary)
plt.xlabel(t_train[i])
plt.show()
컴퓨터는 저 1이라는 숫자를 아래와 같은 형태로 저장합니다. 이를 확인하기 위한 코드를 보면
np.set_printoptions(linewidth = 116, threshold = 1000)
print(x_train[3])
print(t_train[3])컴퓨터는 왼쪽의 이미지를 오른쪽과 같은 형태로 저장을 한다는 것을 확인할 수 있습니다. 이 때 데이터에 정규화를 하게 되면 모든 값이 0과 1 사이로 변하게 되는데, 그러면 아래처럼 나타나게 됩니다.
이 데이터를 통해 신경망을 학습시키고, MNIST 분류기를 만들 수 있습니다. 그러나 위에서 말했듯 이번 포스팅은 학습까지 진행하진 않고 이미 계산되어진 매개변수를 사용할 예정입니다.
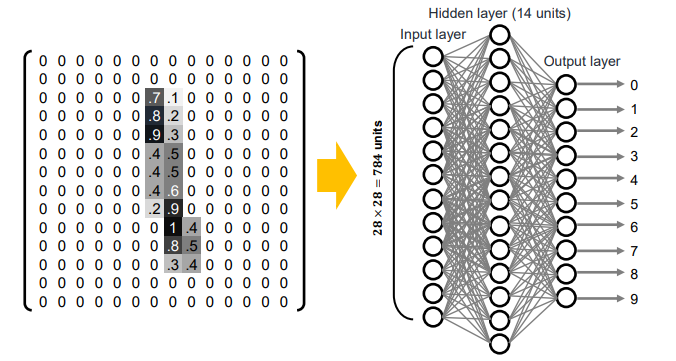
'
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
# Accuracy:0.9352MNIST 데이터셋의 데이터를 가져오는 get_data() 함수, init_network() 는 초기값을 설정해주는 함수인데, 이번에는 가중치와 바이어스 매개변수가 저장되어 있는 .pkl 파일을 읽어와서 사용하게 됩니다. predict 함수는 지난 포스팅에서 살펴본 3중 신경망의 코드입니다. 이 신경망은 입력층 뉴런은 784개(
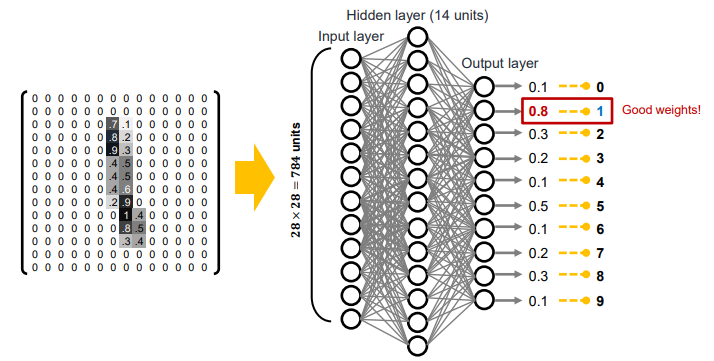
위 사진은 2중 신경망이지만 코드상 구현은 3중 신경망입니다. 첫 번째 은닉층에는 50개, 두 번째 은닉층에는 100개의 뉴런이 배치되어 있습니다. 위 코드에서는 반복문을 돌면서 신경망이 예측한 답변과 정답 레이블을 비교하여 맞힌 숫자를 세고, 전체 이미지 숫자로 나눠 정확도를 나타냅니다. 93.52% 의 정확도를 나타내는 것을 확인할 수 있습니다.
배치 처리
위 코드에서의 가중치 형상을 확인해보면 아래와 같습니다.
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
print(x.shape)
print(x[0].shape)
print(W1.shape)
print(W2.shape)
print(W3.shape)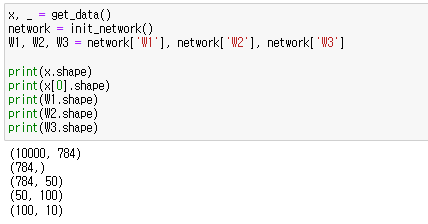

최종 결과로는 원소가 10개인 1차원 배열 Y가 나옵니다. 이는 이미지 1장인 데이터를 입력으로 넣었을 때의 연산입니다.
그렇다면 한번에 여러 개의 데이터를 묶어서 pridict() 함수에 넣는다면?

입력은
x, _ = get_data()
network = init_network()
batch_size = 100
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p= np.argmax(y_batch, axis=1) # 확률이 가장 높은 원소의 인덱스를 얻는다.
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
# Accuracy:0.9352위의 코드를 배치 처리로 구현한 코드입니다. 달라진 부분은 for 문에 step 인수를 추가하여 배치 사이즈 단위로 반복이 실행되고, 반복문의 내부에서는 batch_size 만큼 데이터를 묶어서 예측하고, 최댓값의 인덱스를 가져오는 argmax 함수를 그대로 사용하면서 각 원소에서 최댓값의 인덱스를 찾도록 axis = 1 을 추가해줍니다. ( 100 * 10 이라는 배열에서 1번째 차원인 10 (100은 0번째 차원)의 원에서 탐색을 하도록 )
그리고 if 문 또한 사라진 것처럼 보이지만 == 연산자를 통해 bool 배열을 만들고 True 의 개수를 세서 정확도를 반환합니다. 위 내용에 대한 간단한 동작 예시 코드를 보면 이해가 쉽습니다.
# for 문 3번째 인수 step
print(list(range(0, 10)))
print(list(range(0, 10, 3)))
print()
# argamx axis = 1
x = np.array([[0.1, 0.8, 0.1], [0.3, 0.1, 0.6], [0.5, 0.5, 0.3], [0.8, 0.2, 0.1]])
y = np.argmax(x, axis = 1)
print(x)
print(y)
print()
# Bool 배열 만들어 accuracy 측정
y = np.array([1,2,1,1])
t = np.array([1,2,0,1])
print(y==t)
print(np.sum(y==t))
배치 처리를 사용해 학습을 돌리면 배치 처리를 하지 않았을 때보다 훨씬 속도가 빠릅니다. 위에서 배운 2개의 예시에 대해 각각 수행 시간을 측정해보면 바로 알 수 있습니다.
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
import time
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
w1, w2, w3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
start = time.time()
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
if p == t[i]:
accuracy_cnt += 1
print("배치 처리 O :Accuracy:" + str(float(accuracy_cnt) / len(x)))
print(time.time() - start)
start = time.time()
x, t = get_data()
network = init_network()
batch_size = 100 # 배치 크기
accuracy_cnt = 0
for i in range(0, len(x), batch_size): # 배치사이즈 단위로 반복
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("배치 처리 O : Accuracy:" + str(float(accuracy_cnt) / len(x)))
print(time.time() - start)
'''
출력 :
배치 처리 O :Accuracy:0.9352
0.7629587650299072
배치 처리 O : Accuracy:0.9352
0.1975116729736328
'''
또한 코드를 종합하여 학습이 잘못된 케이스에 대해서 확인할 수도 있습니다.
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
import matplotlib.pyplot as plt
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
w1, w2, w3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
error = []
for i in range(len(x)):
y = predict(network, x[i])
p= np.argmax(y) # 확률이 가장 높은 원소의 인덱스를 얻는다.
if p == t[i]:
error.append(i)
plt.figure(figsize = (10,10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x[error[i]].reshape(28, 28), cmap=plt.cm.binary)
plt.xlabel(t[error[i]])
plt.show()
확실히 결과가 틀린 것에 악필이 많네요.. 아무튼 여기까지 MNIST 데이터셋을 이용한 실습 코드들이었습니다. 감사합니다.

Reference :
밑바닥부터 시작하는 딥러닝 - 사이토 고키
https://ko.wikipedia.org/wiki/MNIST_%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4
https://github.com/WegraLee/deep-learning-from-scratch
'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 정보 엔트로피 ( Information Entropy ) (0) | 2023.08.07 |
|---|---|
| [DL] 손실 함수 ( Loss function ) (0) | 2023.08.03 |
| [DL] 인공 신경망 ( Artificial neural network, ANN ) - Forward Propagation (0) | 2023.07.27 |
| [DL] 활성 함수 ( Activation function ) (0) | 2023.07.26 |
| [DL] 퍼셉트론 ( Perceptron ) (0) | 2023.07.25 |