신경망 학습이란 train 데이터로부터 가중치 매개변수의 최적값을 자동으로 얻는 것을 뜻합니다. 이번 포스팅에서는 신경망이 학습할 수 있도록 해주는 지표인 손실 함수에 대해 알아보도록 하겠습니다.
손실 함수 ( Loss function ) 란?
신경망 학습에서는 현재의 상태를 하나의 지표로 표현합니다. 신경망은 이러한 하나의 지표를 기준으로 최적의 매개변수 값을 탐색하는데, 이 때 신경망 학습에서 사용되는 지표를 손실/비용 함수(Loss function, Cost function) 이라고 합니다. 즉 손실 함수란 신경망의 성능의 '나쁨'을 나타내는 지표로 현재의 신경망이 훈련 데이터를 얼마나 잘 처리하지 못하는가 를 나타냅니다. 인공신경망의 성능이 좋을수록 손실 함수의 값이 낮고 성능이 나쁠수록 손실함수 값이 높게 나타나게 됩니다. 따라서 머신러닝이란, 데이터를 통해 손실함수 값을 낮추는 과정을 말합니다.
이러한 손실 함수는 임의의 함수를 사용할 수 있지만 일반적으로 MSE, cross entropy 등을 사용합니다.
평균제곱오차 (Mean of Squared Error, MSE)
MSE는 가장 많이 쓰이는 손실 함수 중 하나입니다. 다음과 같은 수식으로 나타낼 수 있습니다.
$$ E = \dfrac{1}{2} \sum_k (y_k - t_k)^2 $$
$k$는 데이터의 차원 수, $t_k$는 정답 레이블로 라벨을 one-hot encoding 한 후 $k$번째 좌표, $y_k$는 신경망의 출력으로 신경망이 $k$라고 예측한 확률을 나타냅니다. 예를 들어 소프트맥스를 통과하여 나타났던 이전 MNIST 데이터셋에서의 $y_k$와 $t_k$ 는 다음과 같습니다.
y = [0.05, 0.1, 0.6, 0.05, 0.1, 0.0, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0] # one-hot encoding위 정의는 일반화된 정의는 아니며 이 식은 데이터가 신경망을 거쳐 나온 확률 벡터와 원핫 인코딩을 통해 나온 확률 벡터를 고차원 공간의 점으로 이해한 후, 피타고라스 정리로 거리(유클리드 거리)를 측정하는 방식으로 이해할 수 있습니다.
2차원에 대해서는 $\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}$ 으로 생각할 수 있고, 3차원에 대해서는 $\sqrt{(x_1-x_2)^2+(y_1-y_2)^2 + (z_1-z_2)^2}$ 으로 생각할 수 있고 이를 일반화하면 다음처럼 생각할 수 있습니다.
$$ d = | x - y | = \sqrt{\sum_{i=1}^n |x_i-y_i|^2} $$
중고등학교 때 배운 거리 공식에서 따온 것이며 나중에 미분 계산의 편의를 위해 제곱근을 없애고 앞에 $\dfrac{1}{2}$를 곱한 형태입니다.
이 같은 MSE는 주로 회귀 모델에서 자주 사용되며, MSE에 대한 더 자세한 내용이 궁금하신 분들은 아래 포스팅의 중반부를 참고해주시면 되겠습니다.
[ISL] Statistical Learning ( 통계적 학습 )
Statistical Learning 이란? Statistical Learning (통계적 학습) 이란 데이터를 이해하는 폭넓은 방법을 지칭하며 크게 2가지로 분류할 수 있습니다. 지도 학습 ( Supervised ) 입력(input)에 대한 출력(output)을 통
songsite123.tistory.com
위의 MSE를 통해 분류 모델에서도 클래스별로 정답과 예측의 거리를 계산하고 단순히 더하는 방식으로 오차를 계산하는 것이 가능합니다. 그러나 회귀 문제에서는 단순히 예측과 정답의 차이를 피드백 시키는 것이 중요한 문제이지만, 분류 문제에 있어서 예측한 분류가 정답을 맞췄는지 아닌지는 더 중요한 문제가 됩니다. 예를 들어 정답이 '고양이'인 이미지에 대해 '개' 라고 예측한 경우에는 단순한 확률값과 정답의 차이만큼이 아닌 더 큰 패널티를 줘야만 합니다. 이 때 주로 사용하는 손실 함수가 크로스 엔트로피 입니다.
크로스 엔트로피 (Cross-Entropy)
엔트로피란 불확실성의 척도로 엔트로피가 높다는 것은 정보가 많고 확률이 낮다는 것을 의미합니다. 그 중 크로스 엔트로피는 정보이론에서 나오는 내용으로, 확률 분포 사이의 거리를 재는 방법 중 하나입니다. 이는 모델에서 예측한 확률값이 실제값과 비교했을 때 틀릴 수 있는 정보량을 의미합니다.
$$ E = -\sum_k t_k log y_k $$
$y_k$는 신경망이 $k$라고 예측한 확률을 말하고, $t_k$는 라벨을 one-hot encoding 한 후 $k$번째 좌표를 말합니다. 크로스 엔트로피는 정답과 예측 확률값과의 차이를 계산하고 전부 더해서 오차를 계산하는 방식입니다. 그러나 실제로 계산해보면 one-hot encoding 하여 나온 확률 벡터와 데이터가 신경망을 거쳐 나온 확률 벡터의 크로스 엔트로피는 0으로 날라가는 것이 대부분이기 때문에 만약 라벨이 $k_0$라고 한다면 $E=- \log y_{k_0}$의 형태로 간단하게 나타납니다.
정답에 해당하지 않는 클래스에 대해서는 정답인 0이 곱해지기 때문에 결과가 0이 되고, 정답이 아닌 클래스에 대해서만 -log(예측확률값) 의 형태로 나타나게 됩니다.
만약 예측된 확률값이 정답을 완벽히 맞춘다면 크로스 엔트로피 또한 0이 되어 오차가 0이 되고, 만약 예측한 확률값들이 완전히 틀리게 되면 크로스 엔트로피는 무한대로 커질 수 있습니다.
크로스 엔트로피에 대해 이해하기 어렵고 엄밀하게 따지려면 적분의 개념이 들어가기 때문에 그래프를 제대로 못 보시는 분들이 많은데, 아주 간단히 -logx 그래프만 보고 해석할 수 있습니다.
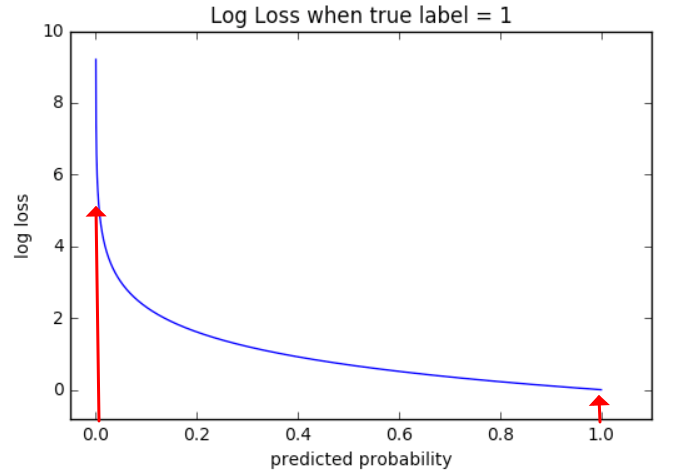
-logx 의 개형을 대략 나타낸 그래프입니다. 이 때 가로축이 predicted probability, 예측 확률인 것을 주목하시길 바랍니다. 또한 세로축이 곧 loss(=크로스 엔트로피) 가 됩니다. 만약 분류가 제대로 되었다면 신경망의 성능의 나쁨 지표를 나타내는 손실함수는 값이 작아야겠죠? 손실 함수값은 곧 세로축입니다. 따라서 왼쪽의 화살표와 오른쪽의 화살표 중 더 작은 손실함수 값을 가지는 것은 당연히 오른쪽 화살표입니다. 오른쪽 화살표의 예측 확률이 훨씬 높다는 것은 정답 레이블에 대해 제대로 맞췄다는 것을 의미합니다. 만약 정답을 맞추지 못했다면 높은 확률을 가져봤자 0이 곱해지기 때문에 낮은 predicted probability 를 가지게 되고 따라서 높은 log loss 를 가지게 되며 이는 곧 높은 크로스 엔트로피를 가진다고 해석할 수 있는 것입니다.
크로스 엔트로피는 어려운 내용이고 중요한 내용이기 때문에 다음 포스팅에서 따로 엔트로피와 크로스 엔트로피에 대해 다룰 예정입니다.
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
def cross_entropy_error(y, t):
if y.ndim == 1: # 배치 처리를 안한 y가 입력되었다면 행렬 변환
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 훈련 데이터가 one-hot vector 라면 정답 레이블의 인덱스로 변환,
# one-hot encoding이 안된 경우도 사용할 수 있도록 one-hot encoding 하기 전으로 되돌리는 코드
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t])) / batch_sizeMSE와 크로스 엔트로피에 대한 코드를 보면서 마무리하도록 하겠습니다. 감사합니다.

Reference :
밑바닥부터 시작하는 딥러닝 (저자 : 사이토 고키 / 번역 : 이복연 / 출판사 : 한빛미디어)
https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
'딥러닝(DL) > 딥러닝 기초' 카테고리의 다른 글
| [DL] 수치 미분 ( Numerical differentiation ) (0) | 2023.08.11 |
|---|---|
| [DL] 정보 엔트로피 ( Information Entropy ) (0) | 2023.08.07 |
| [DL] MNIST ( Modified National Institute of Standards and Technology database ) (0) | 2023.07.31 |
| [DL] 인공 신경망 ( Artificial neural network, ANN ) - Forward Propagation (0) | 2023.07.27 |
| [DL] 활성 함수 ( Activation function ) (0) | 2023.07.26 |