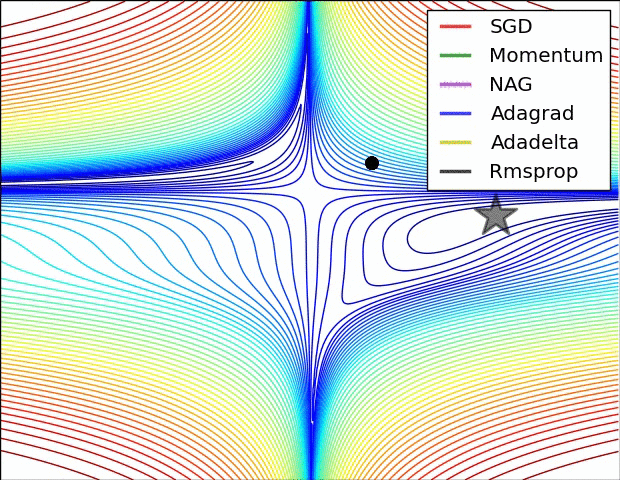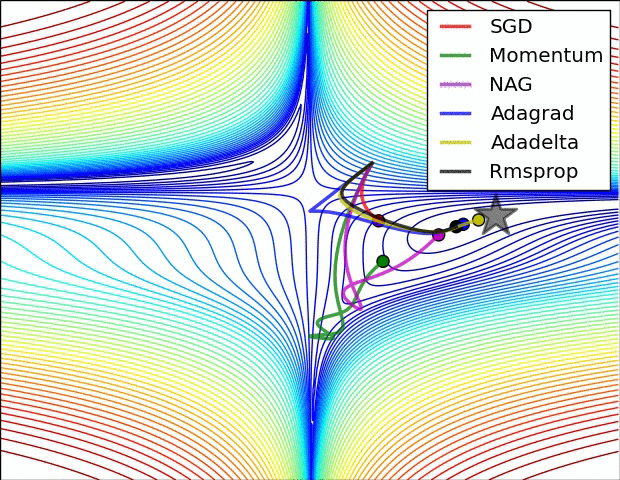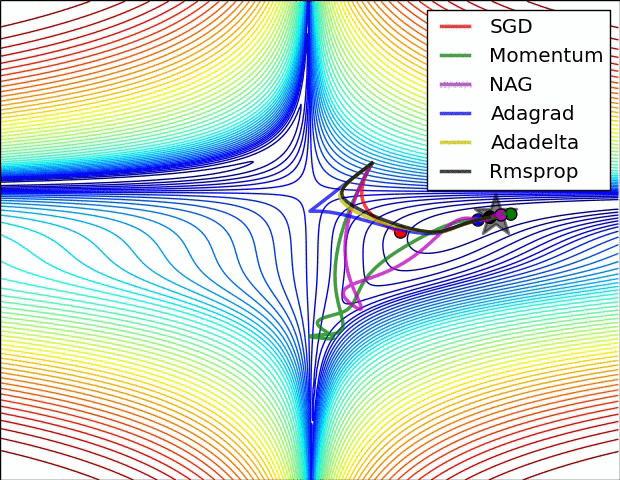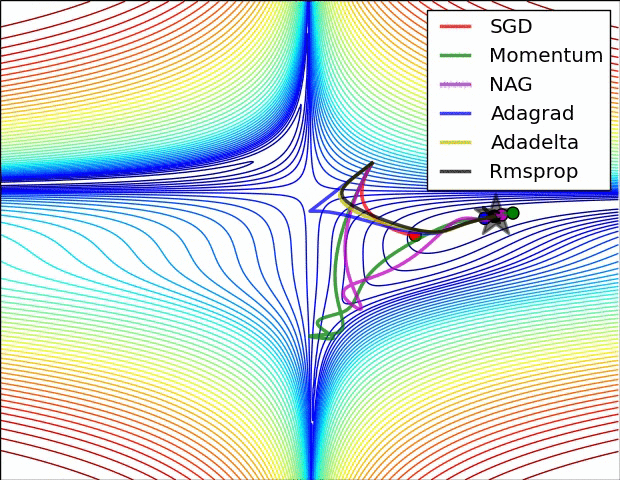
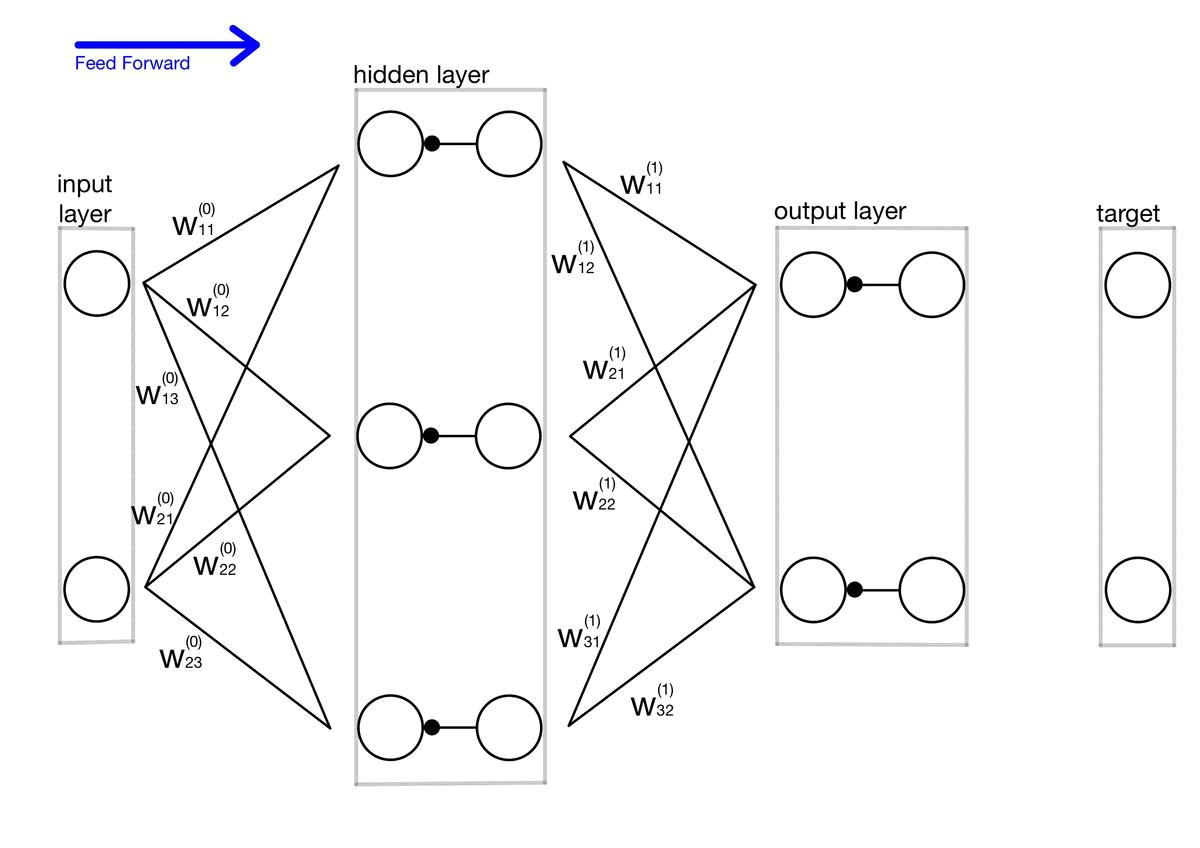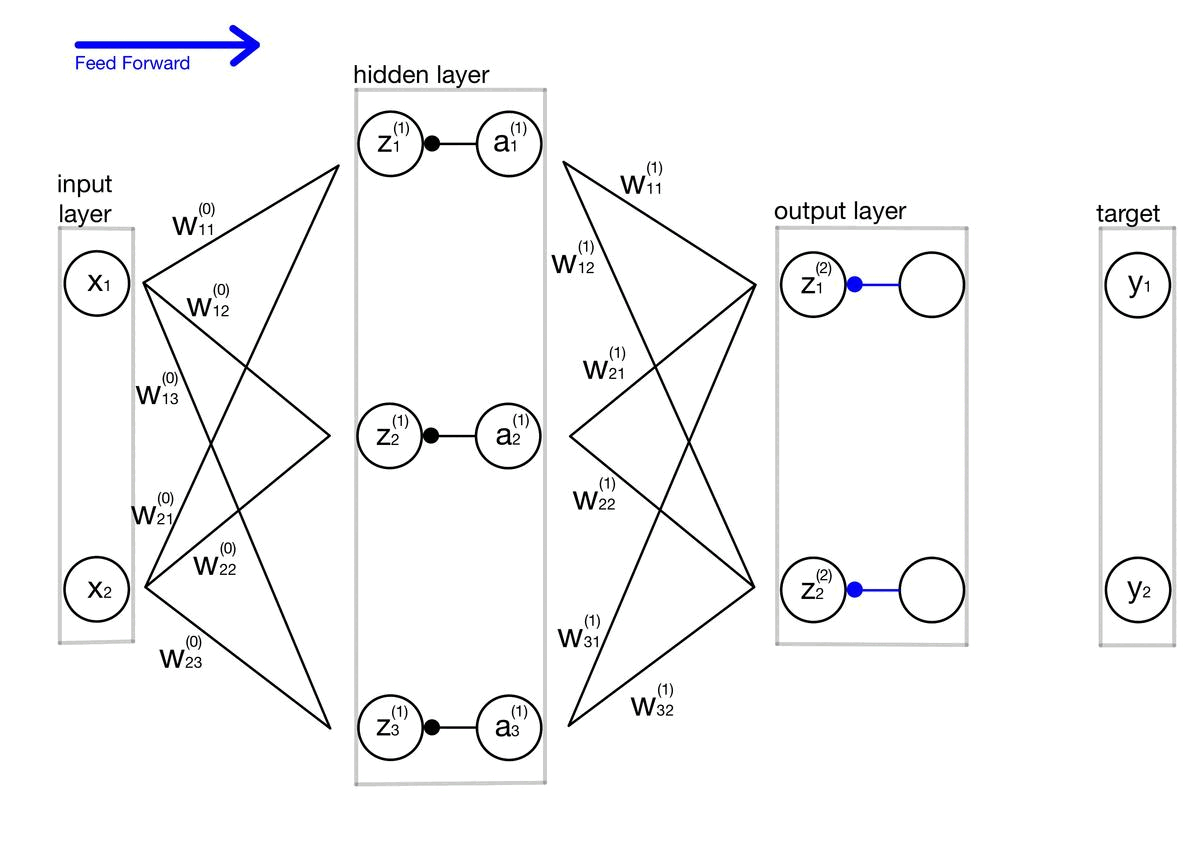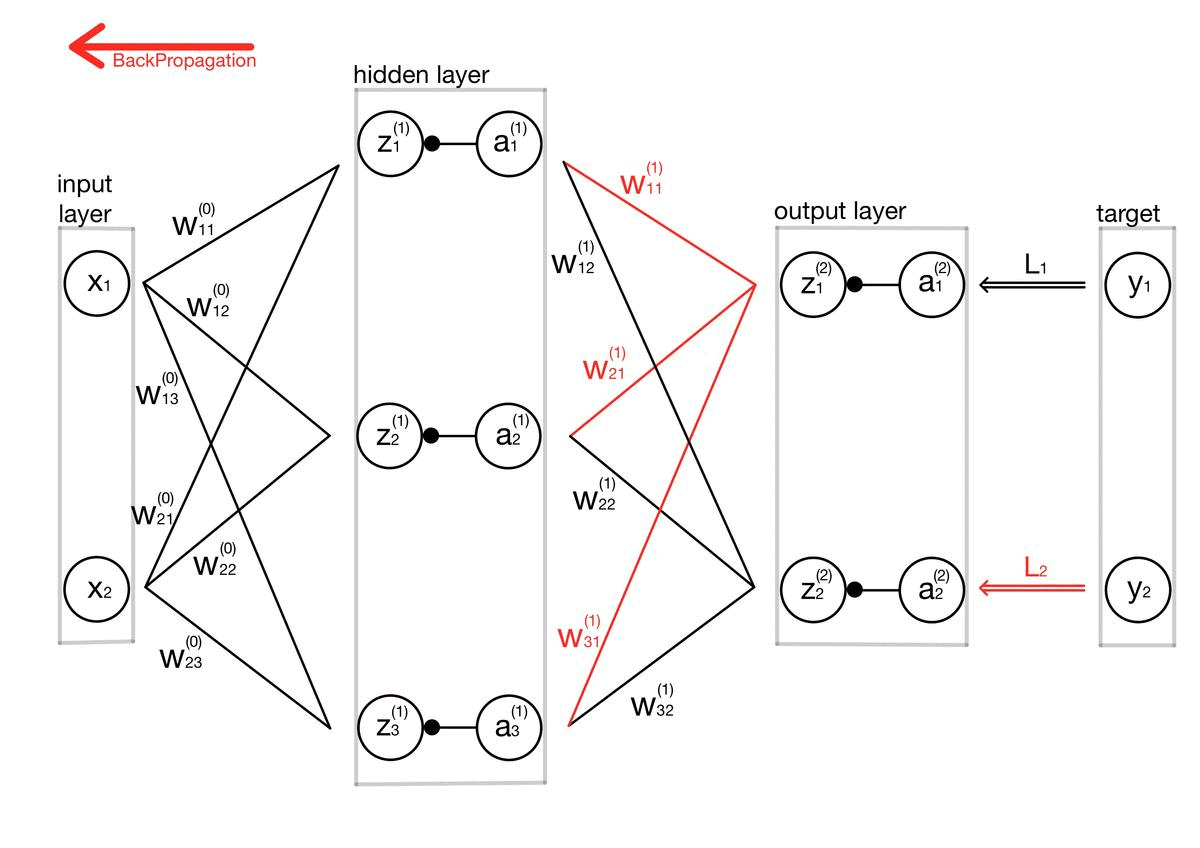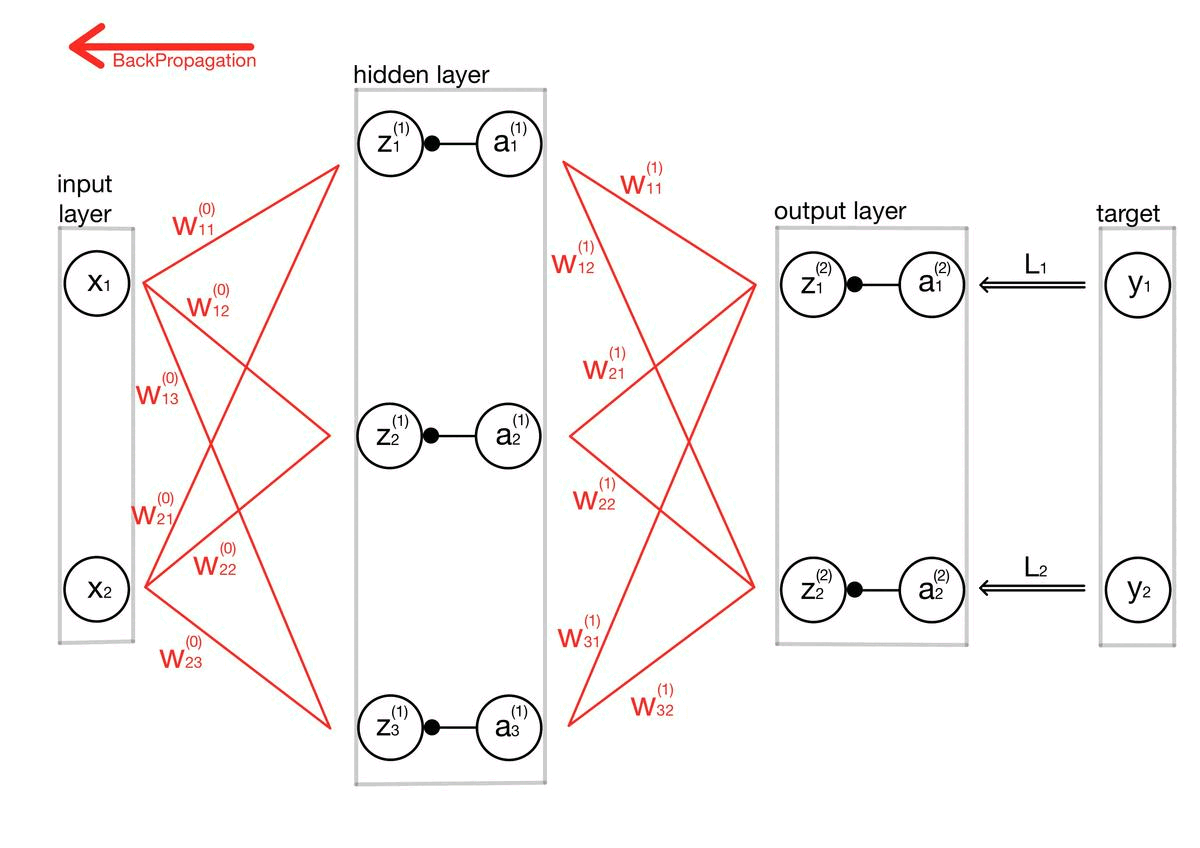
적대적 공격(Adversarial attack) 이란 딥러닝 모델의 취약점을 이용하여 만든 공격 방법으로, 특정 노이즈값을 이용해 의도적으로 오분류를 이끌어내는 입력값을 만들어 내는 것을 의미합니다. 논문 내 이미지를 통해 예를 들어보면 왼쪽 이미지는 누가 봐도 판다 사진이죠. 가운데 노이즈 이미지는 사람이 보기에 전혀 의미가 없는 이미지 처럼 보입니다. 그러나 가운데 노이즈는 특정 feature 값을 가지고 있는 의도적으로 만들어낸 노이즈이고, 실제로 왼쪽의 판다와 가운데 사진을 더해서 만든 사진이 오른쪽 사진인데, 육안으로 보기에는 똑같아 보이지만 오른쪽 사진은 gibbon, 긴팔 원숭이로 딥러닝 모델이 분류하고 있는 겁니다. 즉 딥러닝 모델은 사람보다 훨씬 자세하게 이미지의 정보를 학습하기 때문에,..