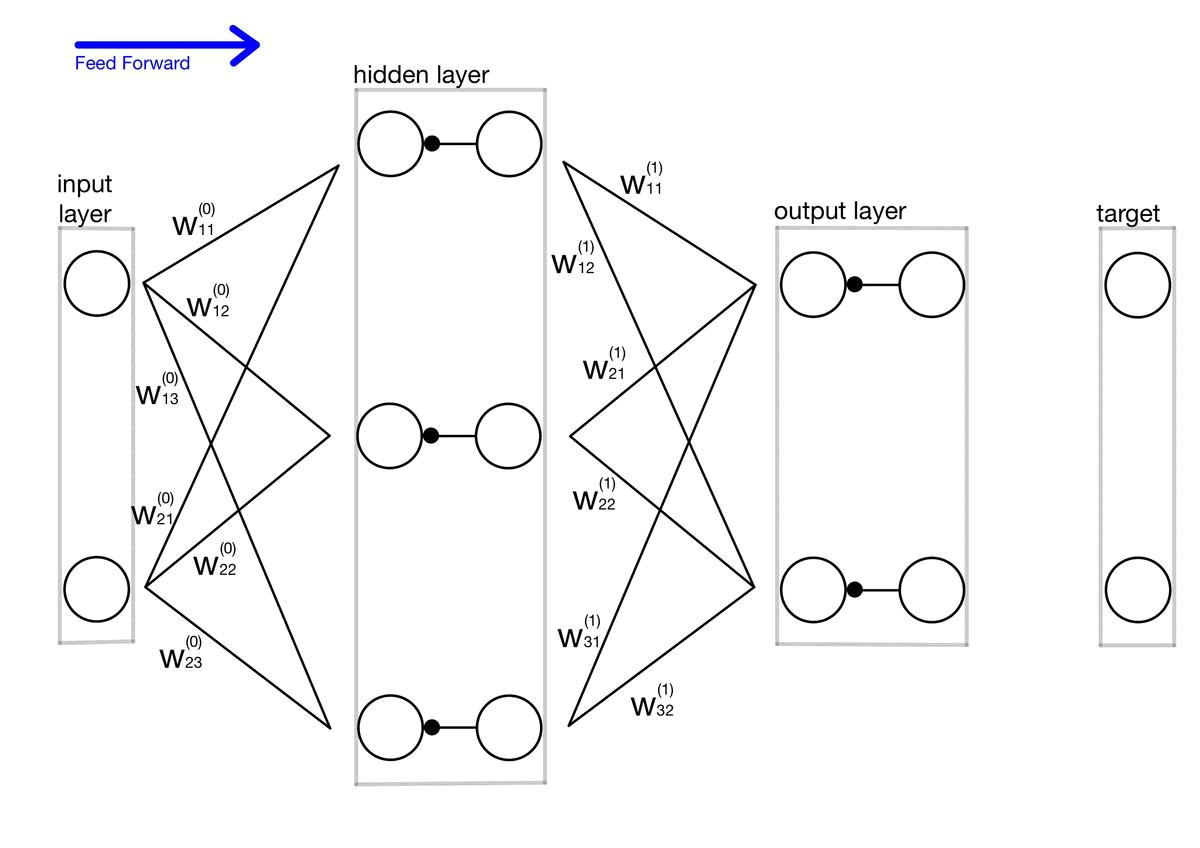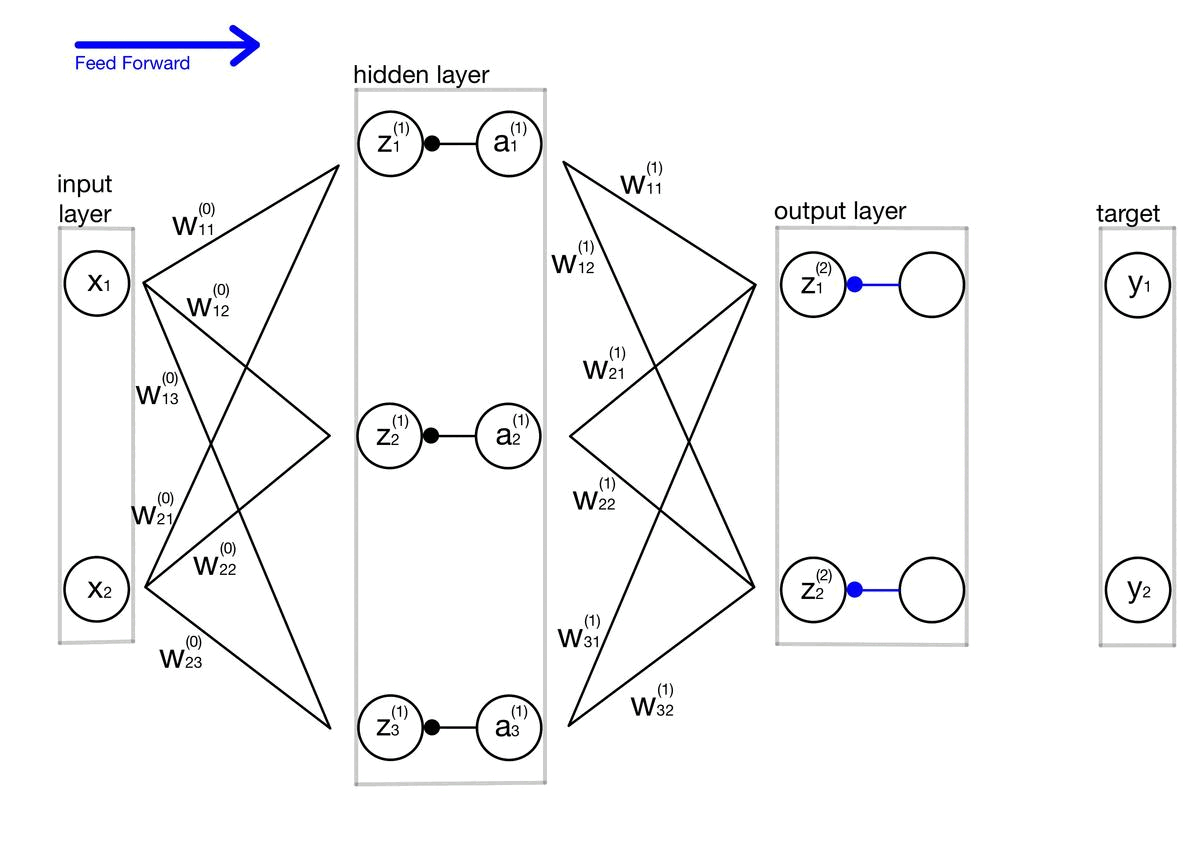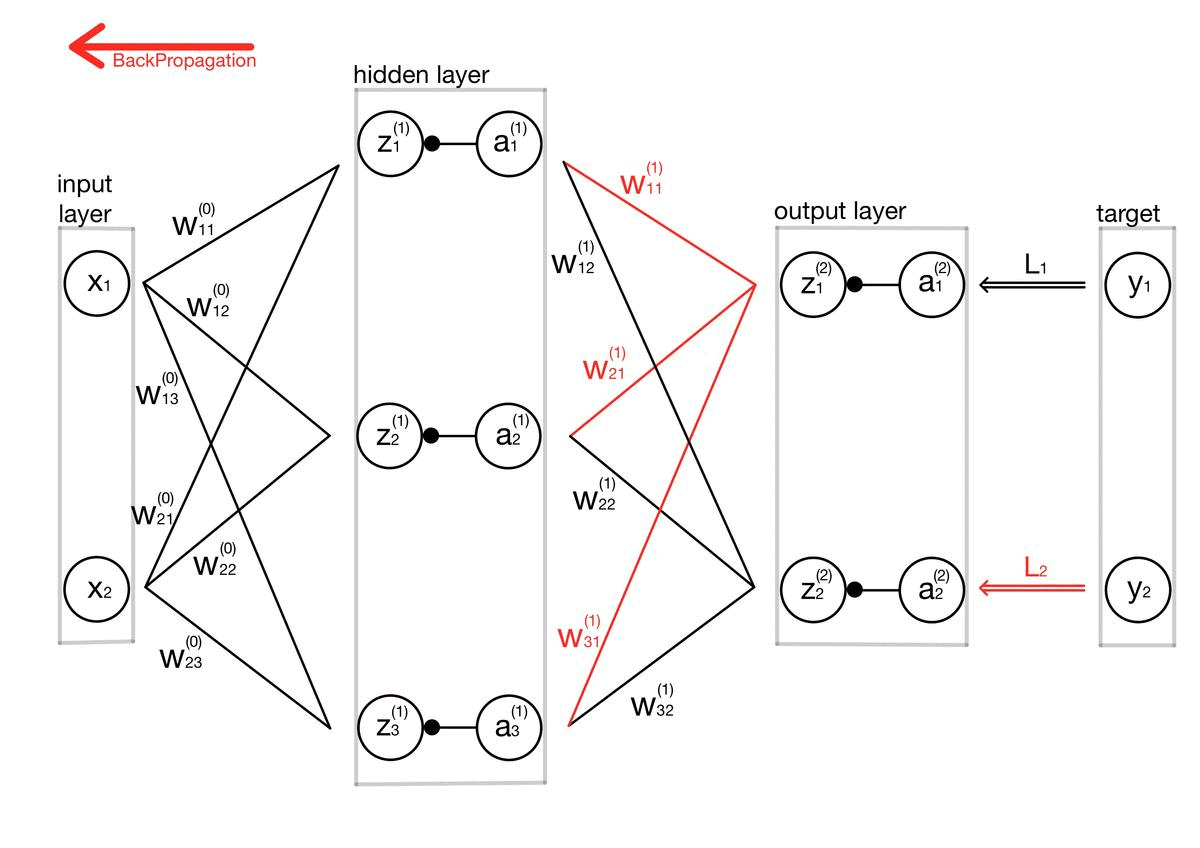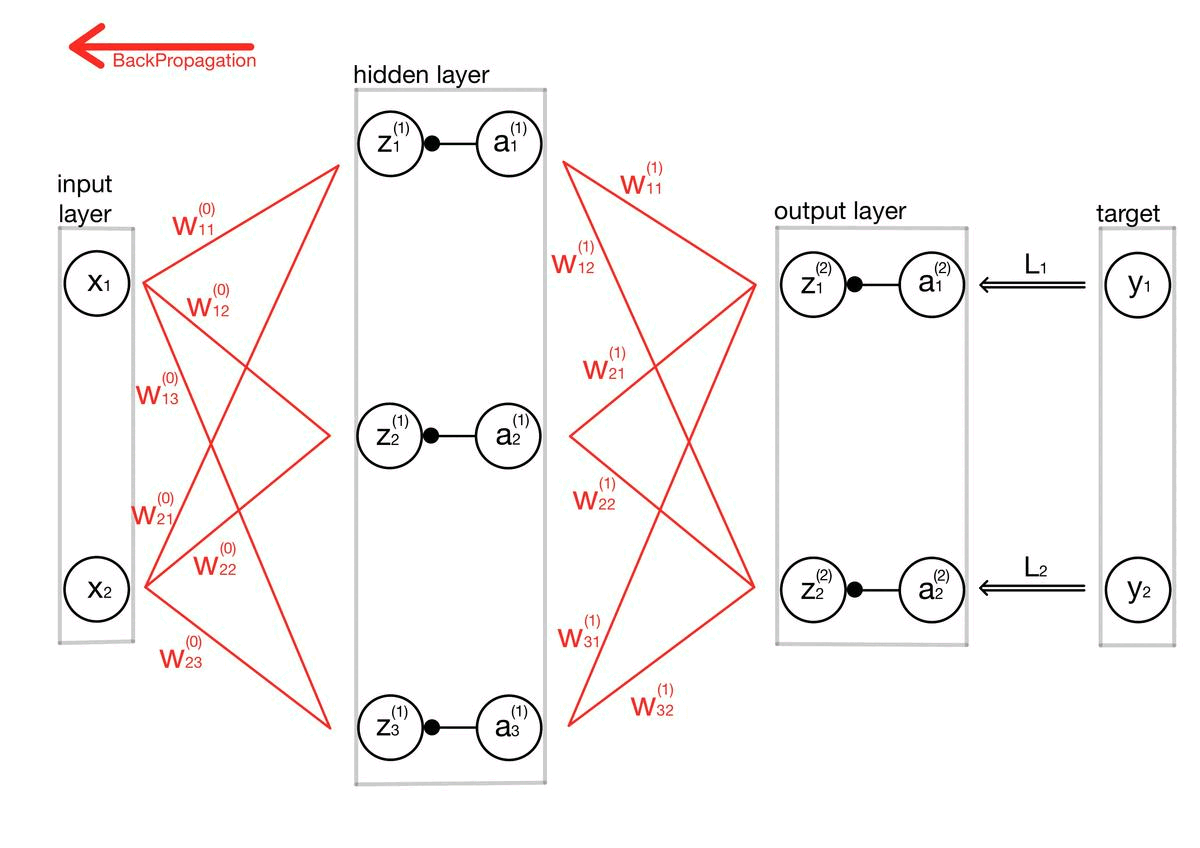
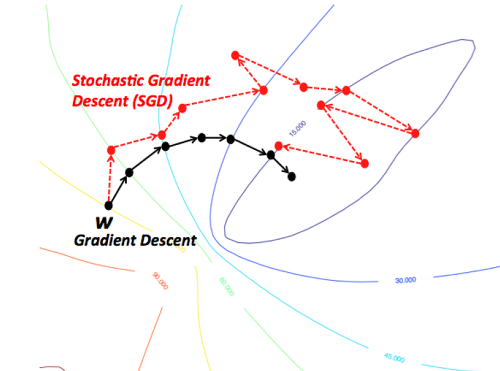
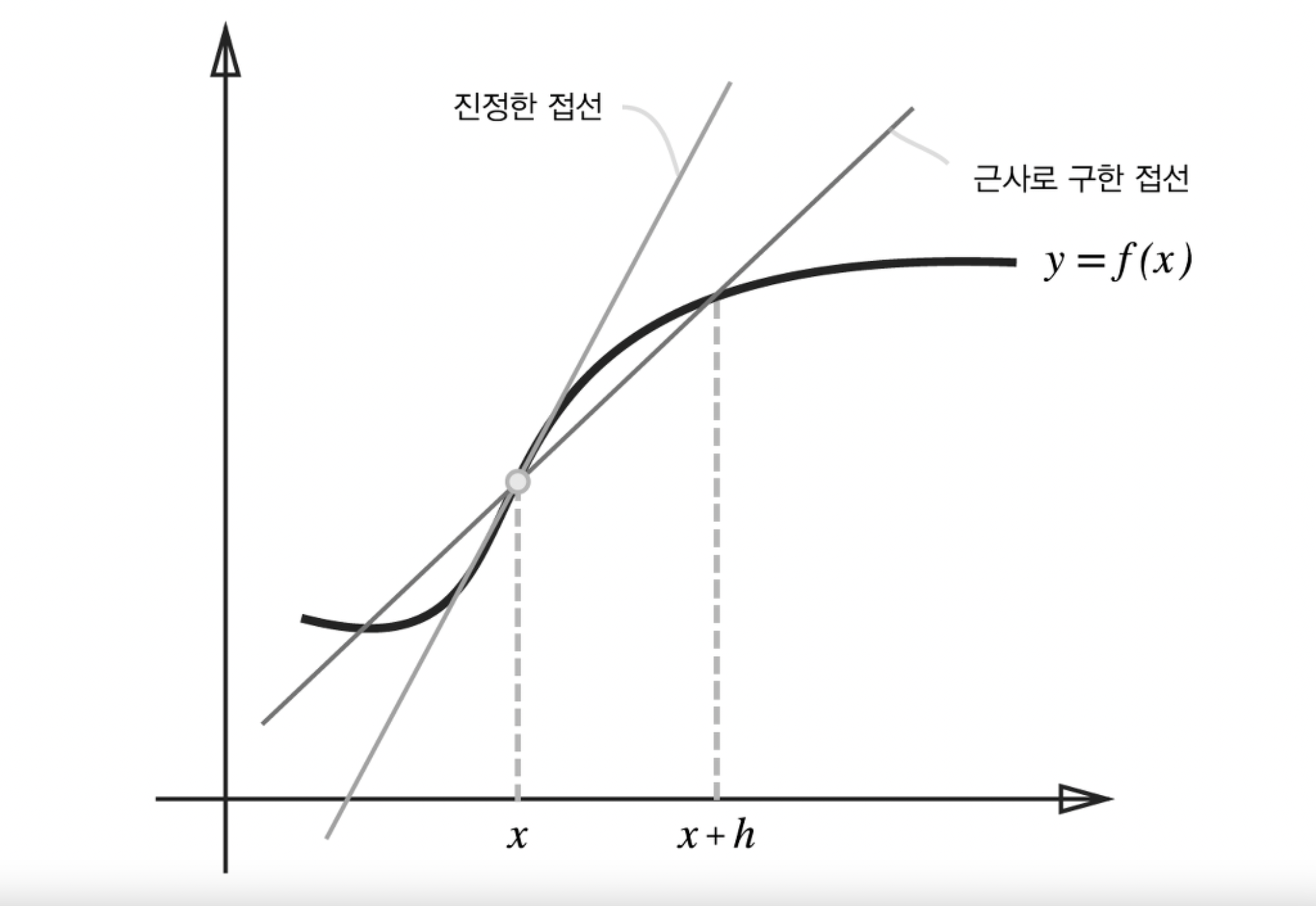
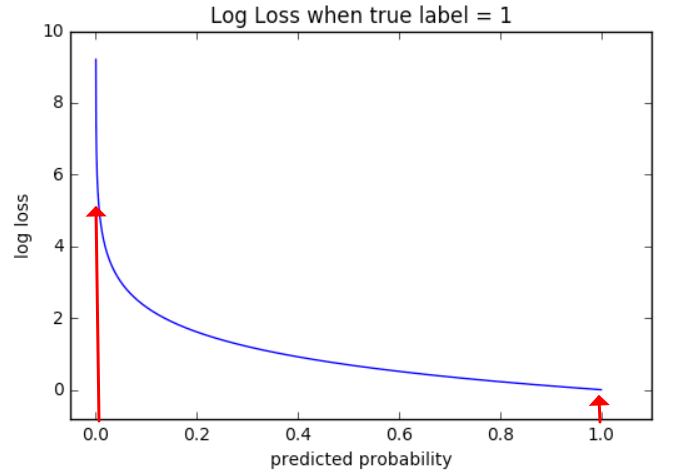
구현이라기보단 제가 스스로 이해하기 위해 주석 및 설명을 달아놓는 포스팅입니다. 개념 설명이 아닌 포스팅이라 코드를 보실 분 아니면 넘어가셔도 좋을 것 같습니다. # coding: utf-8 import sys, os sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정 import numpy as np from common.layers import * from common.gradient import numerical_gradient from collections import OrderedDict class TwoLayerNet: def __init__(self, input_size, hidden_size, output_size, weight_init_std..